GDPval: Measuring AI's Economic Impact
衡量 AI 对经济影响的指标:
- Adoption Rates 采纳率
- Usage Patterns:使用模式
- GDP Growth attributed to AI
理解 AI 的潜在经济影响的替代方法:直接衡量 AI 模型的能力
GDPval 包含贡献美国 GDP 最多的 9 大行业,每个职业至少有 30 个任务(gold subset 里每个至少有 5 个任务) ⇒ 44 个职业
评估指标:自动化评估这些复杂任务存在问题。主要指标:head-to-head human expert comparison。提供一个实验性的自动评分器 for 220 个 golden subtasks
与现有 benchmark evaluation 的优势:
- Realism:现有 benchmark 更关注 reasoning difficulty,GDPval 基于实际产品,经过多轮验证,和完成所需的 time and cost 紧密联系
- Representative breadth:现有 benchmark 关注 domain-specific task,GDPval 全集包含 1320 tasks 覆盖 44 个职业。来源于美国劳工部就业与培训管理局(2024),用于覆盖 O*NET 为每种职业所追踪的大多数工作活动
- Computer use and multi-modality:需要处理各种格式(CAD 设计文件、照片、视频、音频、社交媒体帖子、图表、PPT、电子表格、客户支持对话)。每个任务还需要解析 golden subset 中的最多 17 个参考文件,以及完整集合中的 38 个文件
- Subjectivity:除正确性外,专家评估通常考虑主观因素,如结构、风格、格式、美学和相关性 ⇒ 验证自动评分器性能
- No "upper limit":主要指标是 win rate,允许持续评估。将 model outputs 与 human expert baseline 进行评估,后续可以用更强大的模型来替换 human baselines
- Long-Horizon Difficulty:每个 task 平均需要专家 7 个小时完成。高端任务可能需要数周
Task Creation
包含 9 个行业和 44 个职业,年总收入达 3 万亿美元。
选择标准:选择对美 GDP 贡献在 5% 以上的行业
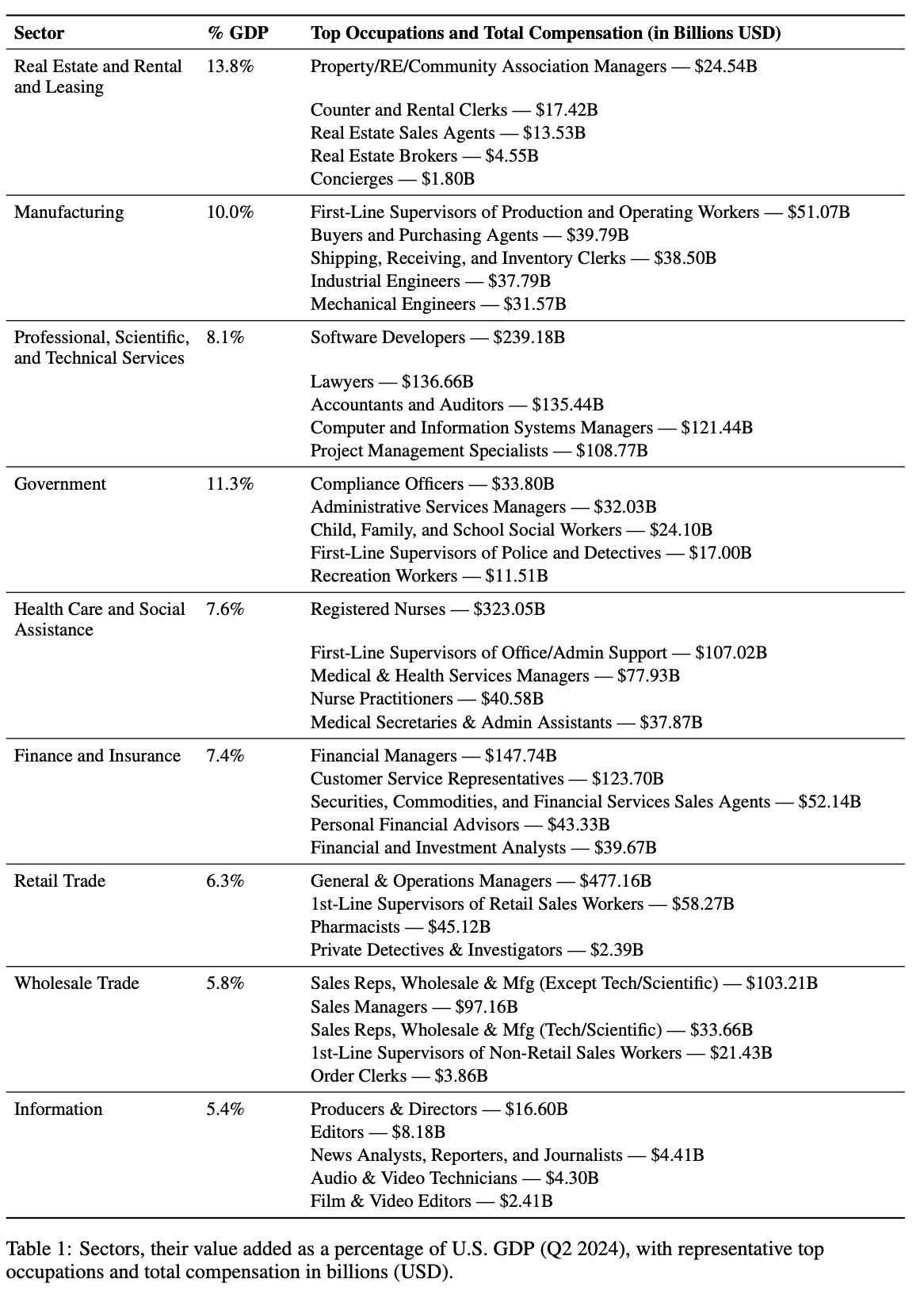
选择每个行业中贡献最多的 5 个职业(工资高、数字化)
基于 task 的方式来看职业是否被分类为数字化:识别了来自 O*NET 的职业数据、定义和任务数据库中的所有任务。Prompt GPT-4o 分类每个任务是否数字化;将每个职业整体的数字化任务率 > 60%,认为该职业数字化。
根据"相关性"、"重要性"和"频率"对 O*NET 任务评分中报告的每个任务的得分进行了加权。进一步通过将其与 Acemoglu & Autor (2011) 的任务内容框架进行对比,验证数字化任务衡量指标的代表性。
我们观察到的相关性——数字任务随着非常规认知内容的增加而增加,随着常规和手动内容的增加而减少——表明与已有的经济工作衡量标准相一致。
使用了 O*NET 2024 年 5 月的全国就业和工资估计数据,来计算 831 个职业的总工资

任务构成
每个任务包含两个主要的模块:a request (often with reference files) and a deliverable (work product)
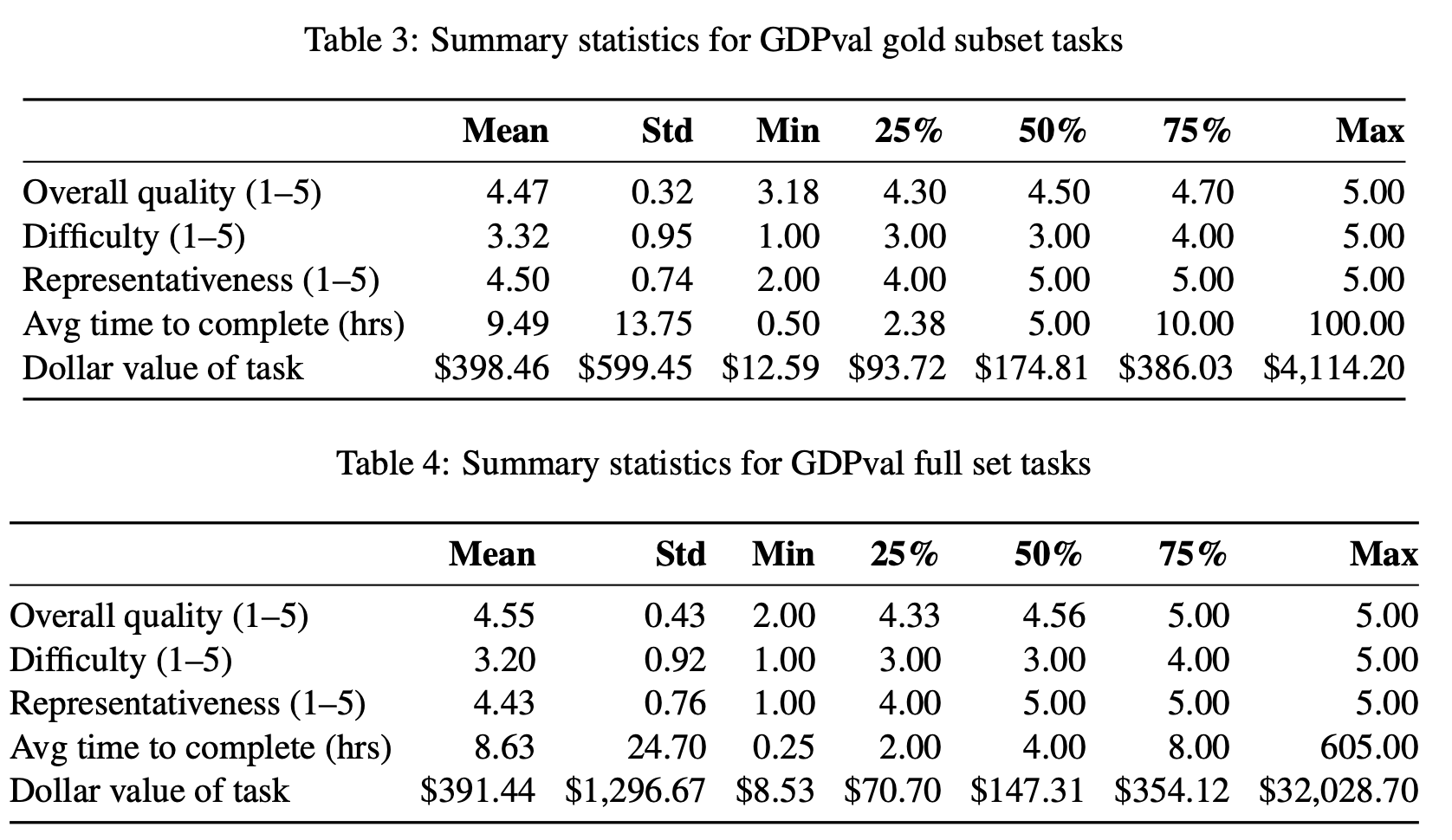
GDPval 的任务需要与多种类型的文件进行交互,67.7% 的任务需要与至少一个 reference file 进行交互
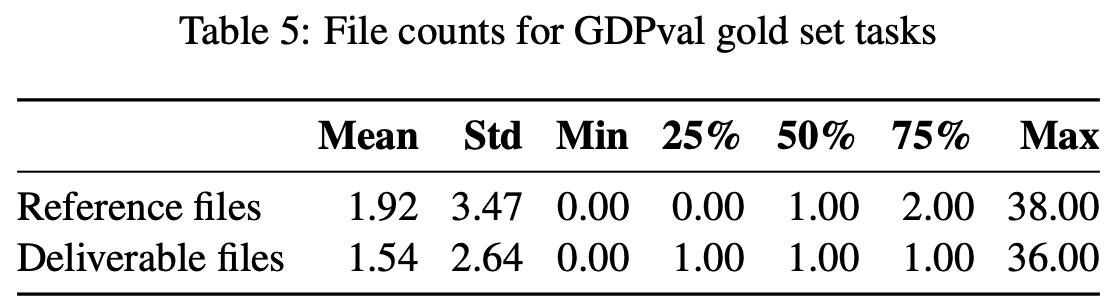
质量控制
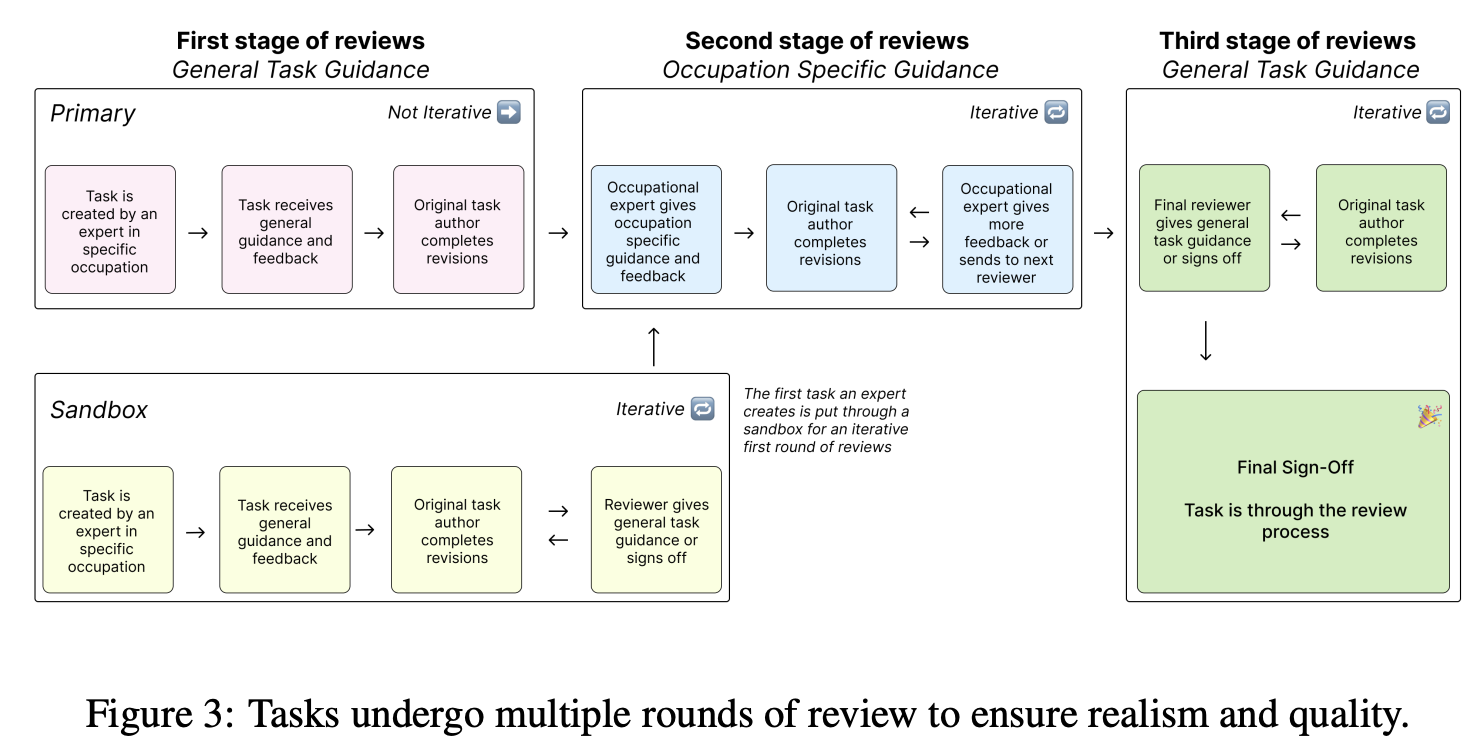
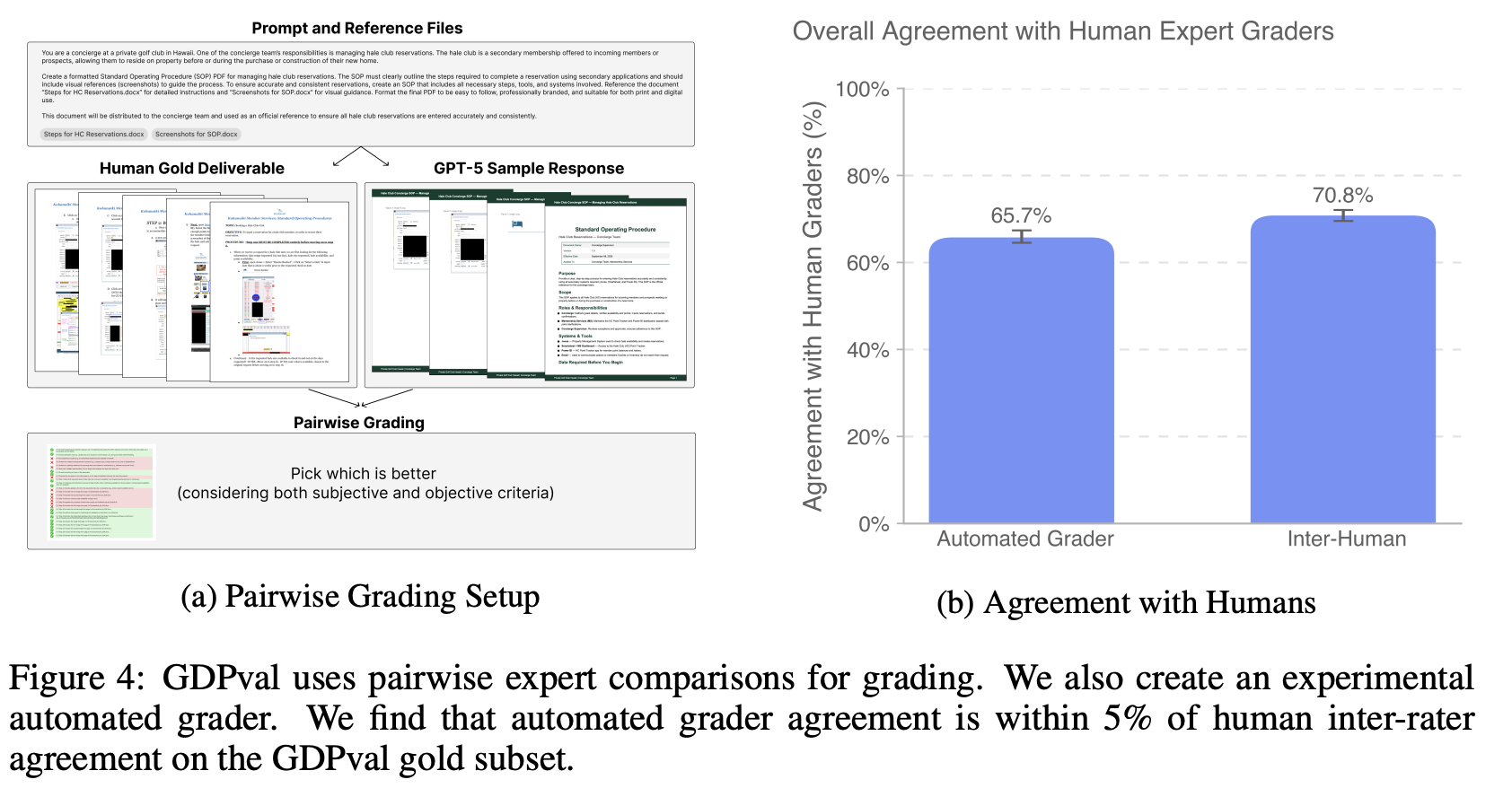
人类专家打分和自动化评估
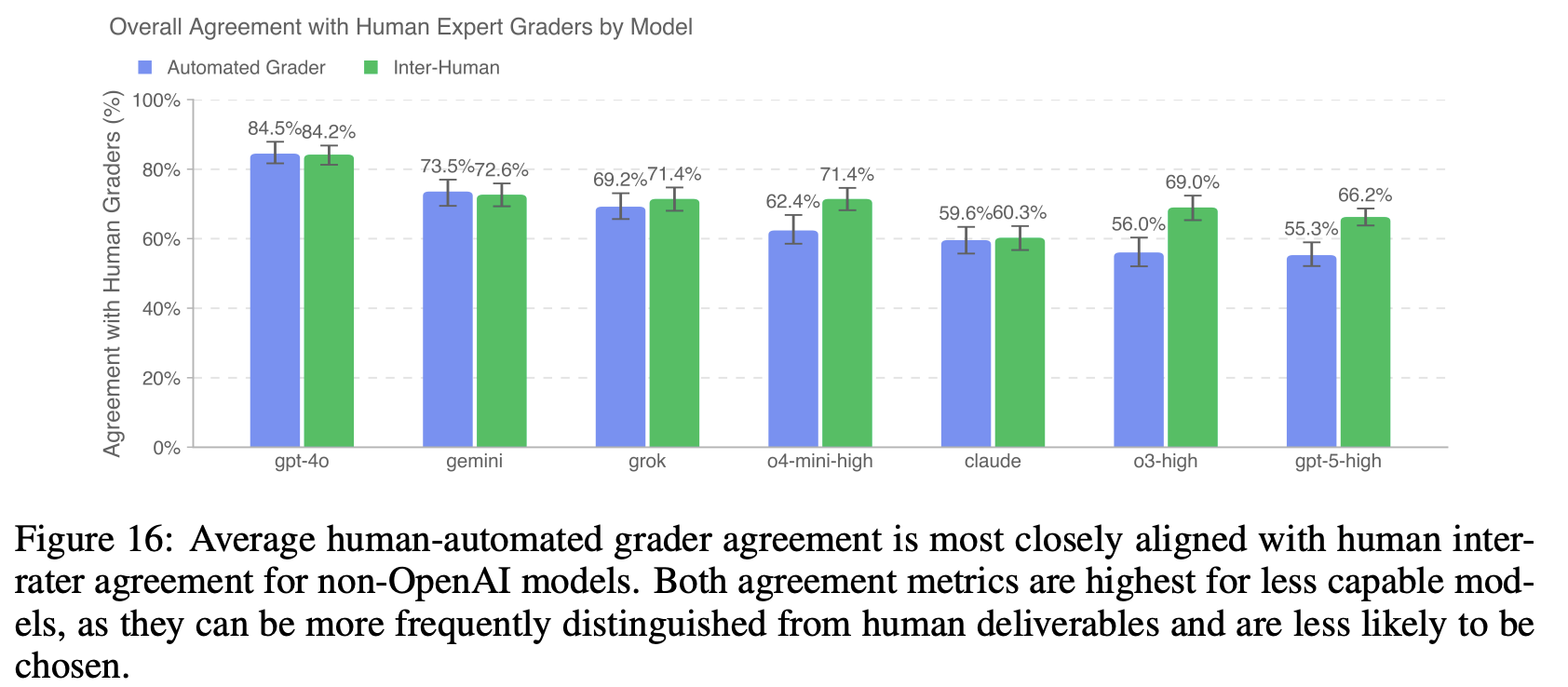
对于 golden subset,训练了一个实验性的评分模型,以进行行业专业专家风格的成对比较。尽管有限,但自动评分器比专家评分更快、更便宜。与人工专家评分者达成 66% 的一致性,仅比人类专家评分者 71% 的互评一致性低 5%。
自动评分器共识指标:
- 人类-评分器一致性:$A_s^{HA} = \mathbb{E}[1 - |H - A|]$,其中 $A \in \{0, 0.5, 1\}$
- 人类间一致性:$A_s^{HH} = \mathbb{E}[1 - |H_1 - H_2|]$
Results
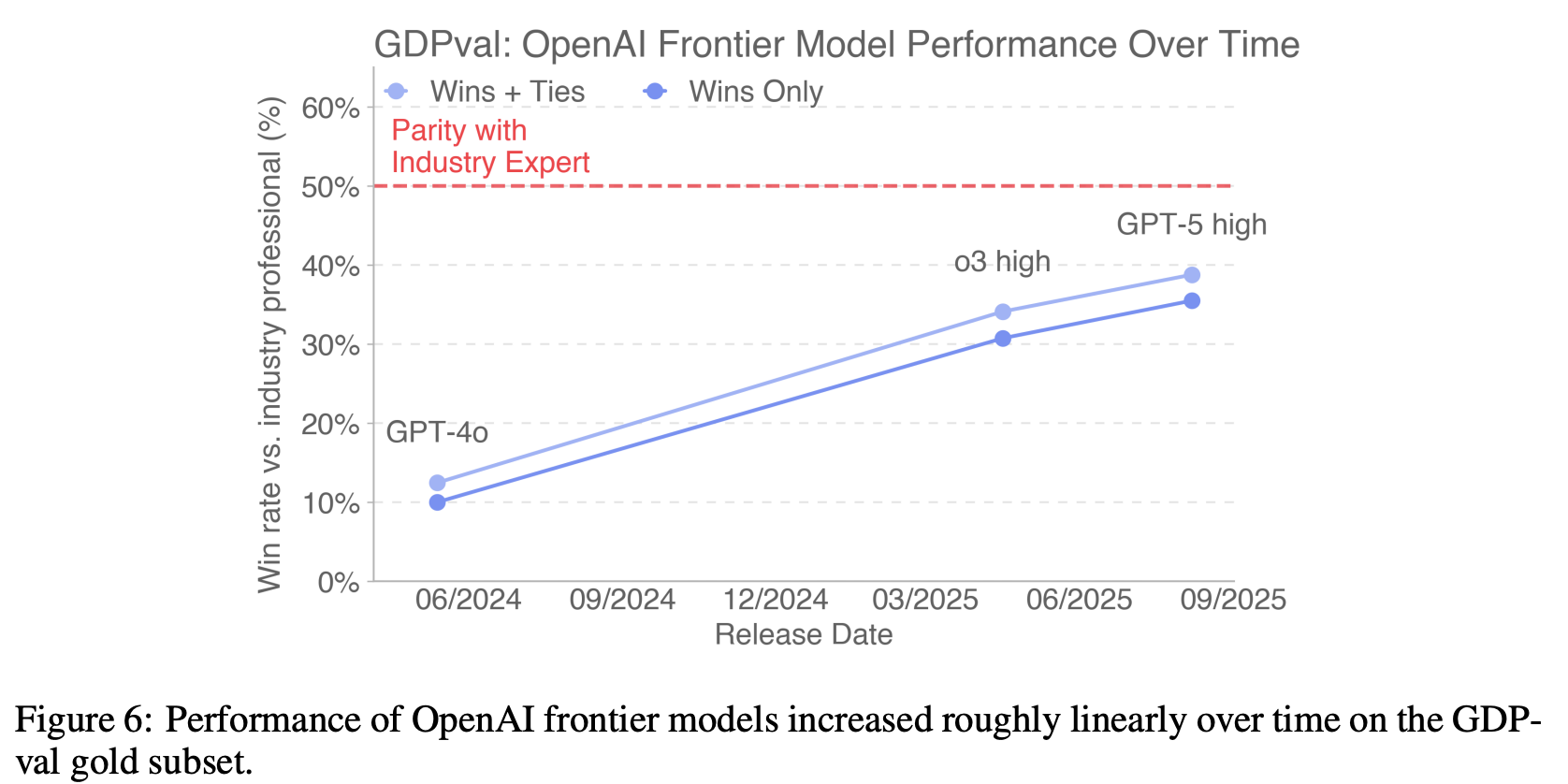
在 Golden Subset 上的实验结果
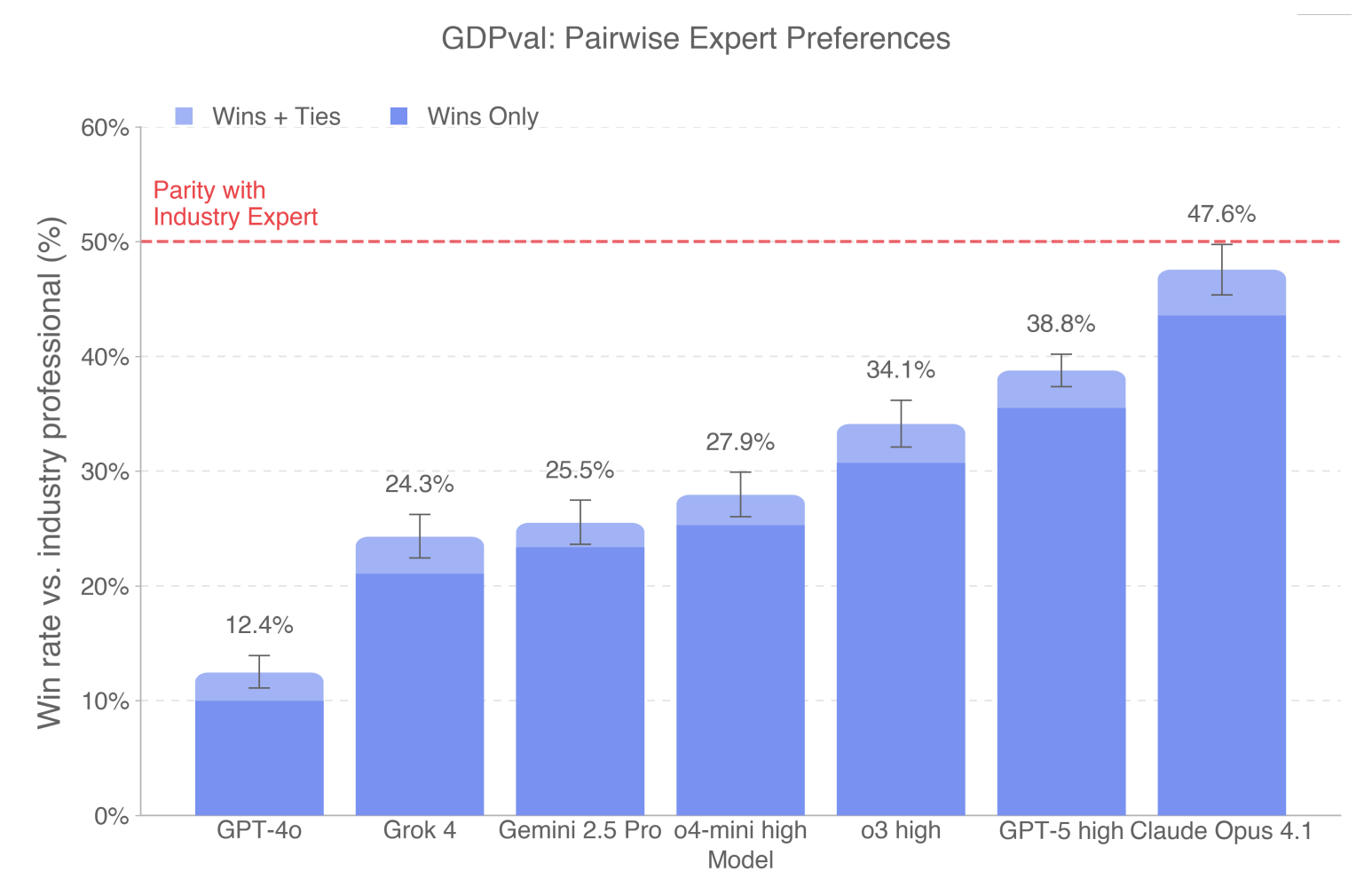
Claude 在美学表现上更好,GPT-5 在 Accuracy 上更擅长(遵循指令、执行正确计算)。GPT-5 在纯文本任务上表现更好,Claude 在 .pdf .xlsx .ppt 等文件类型上表现更好
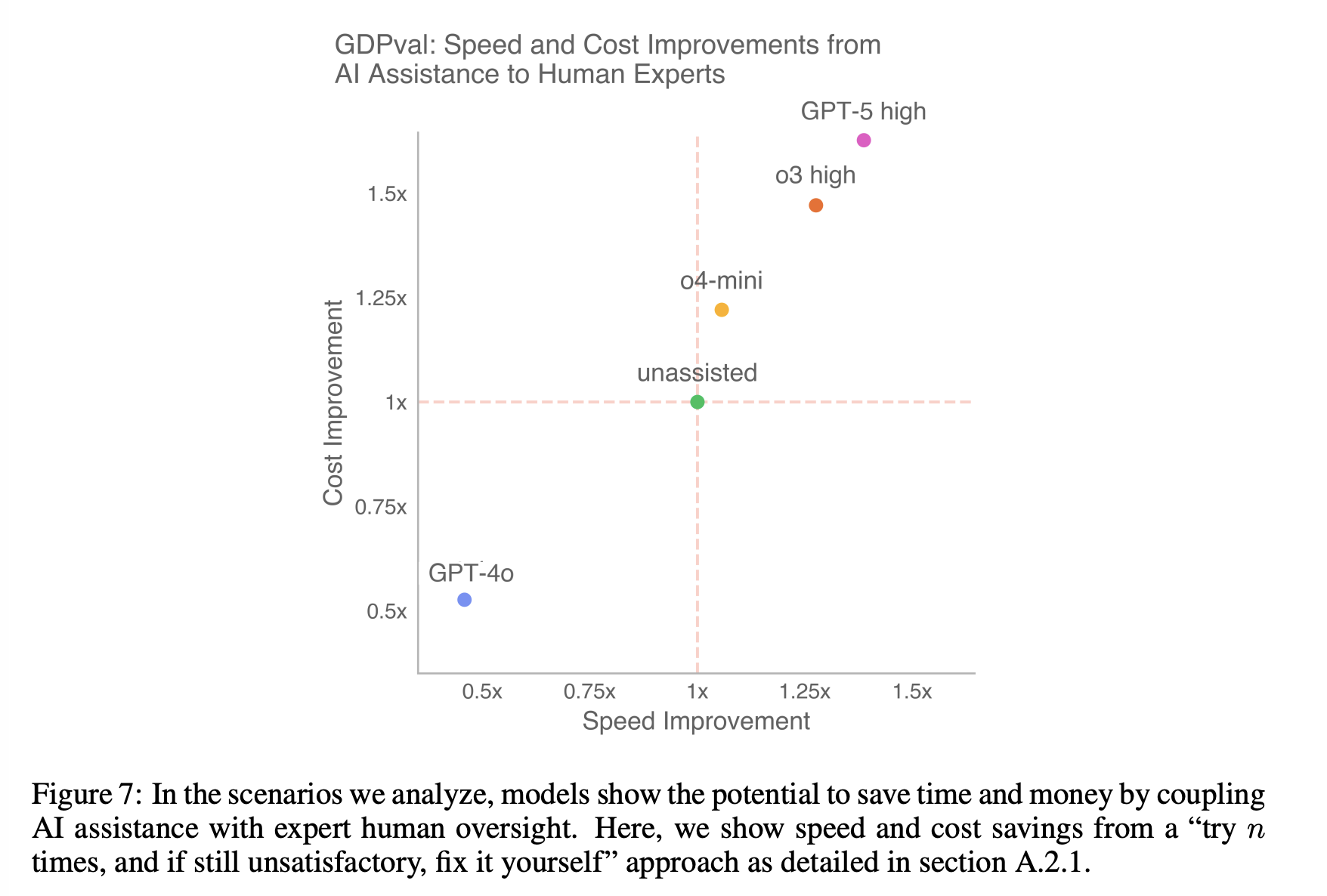
效率和成本
为 Human Experts 提供 AI 助手后可以提升其工作效率。从"尝试 n 次,如果仍不满意,自己修复"的方法中获得的速度和成本节约
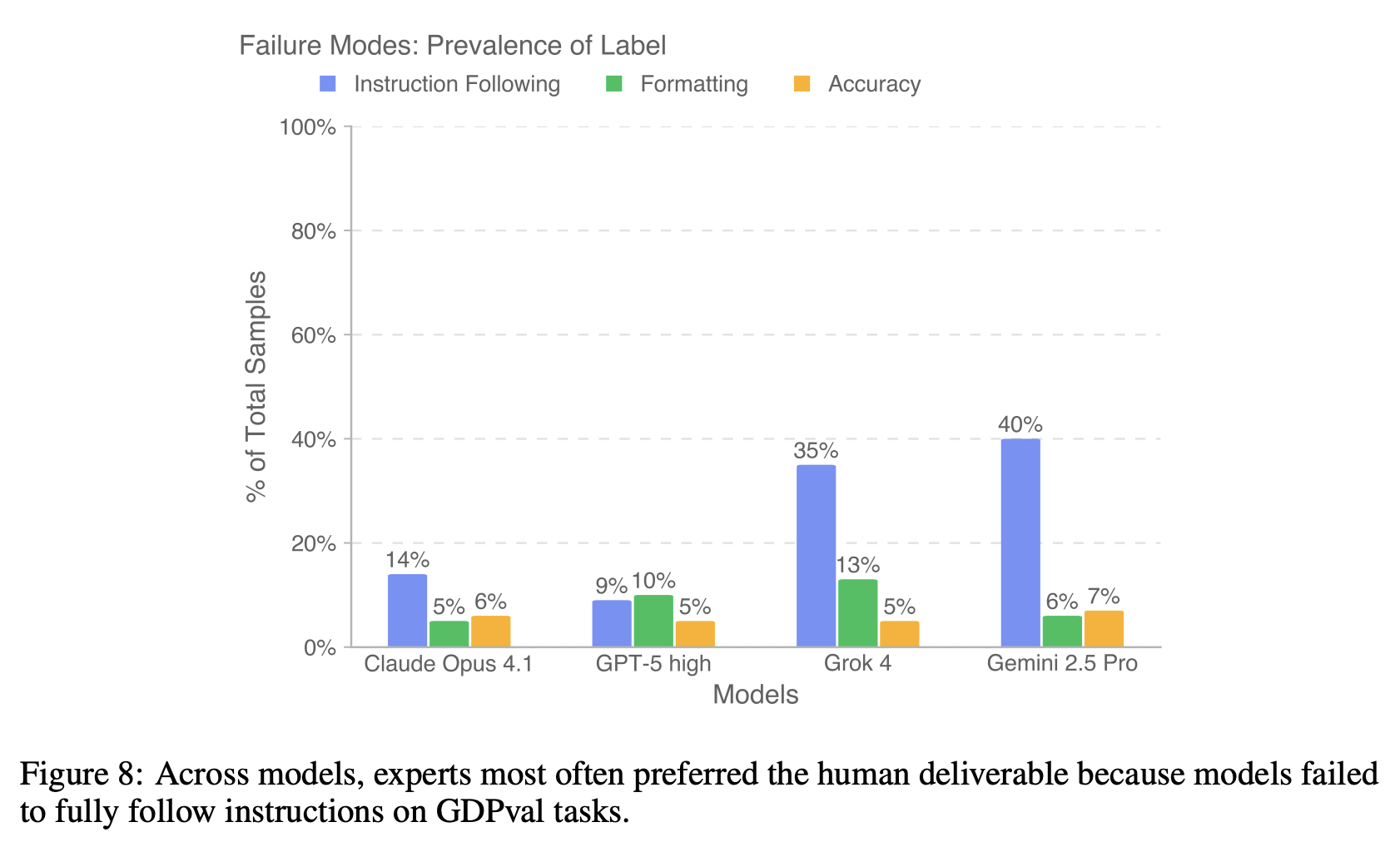
模型强项与弱点
- Claude、Grok 和 Gemini 最常因指令执行失败而丢分
- GPT-5 主要因格式错误丢分,且指令执行问题最少
- Gemini 和 Grok 经常承诺但未能提供交付成果,忽略参考数据或使用错误的格式
- 尽管所有模型有时都会产生数据幻觉或计算错误,但 GPT-5 和 Grok 的准确性错误最少
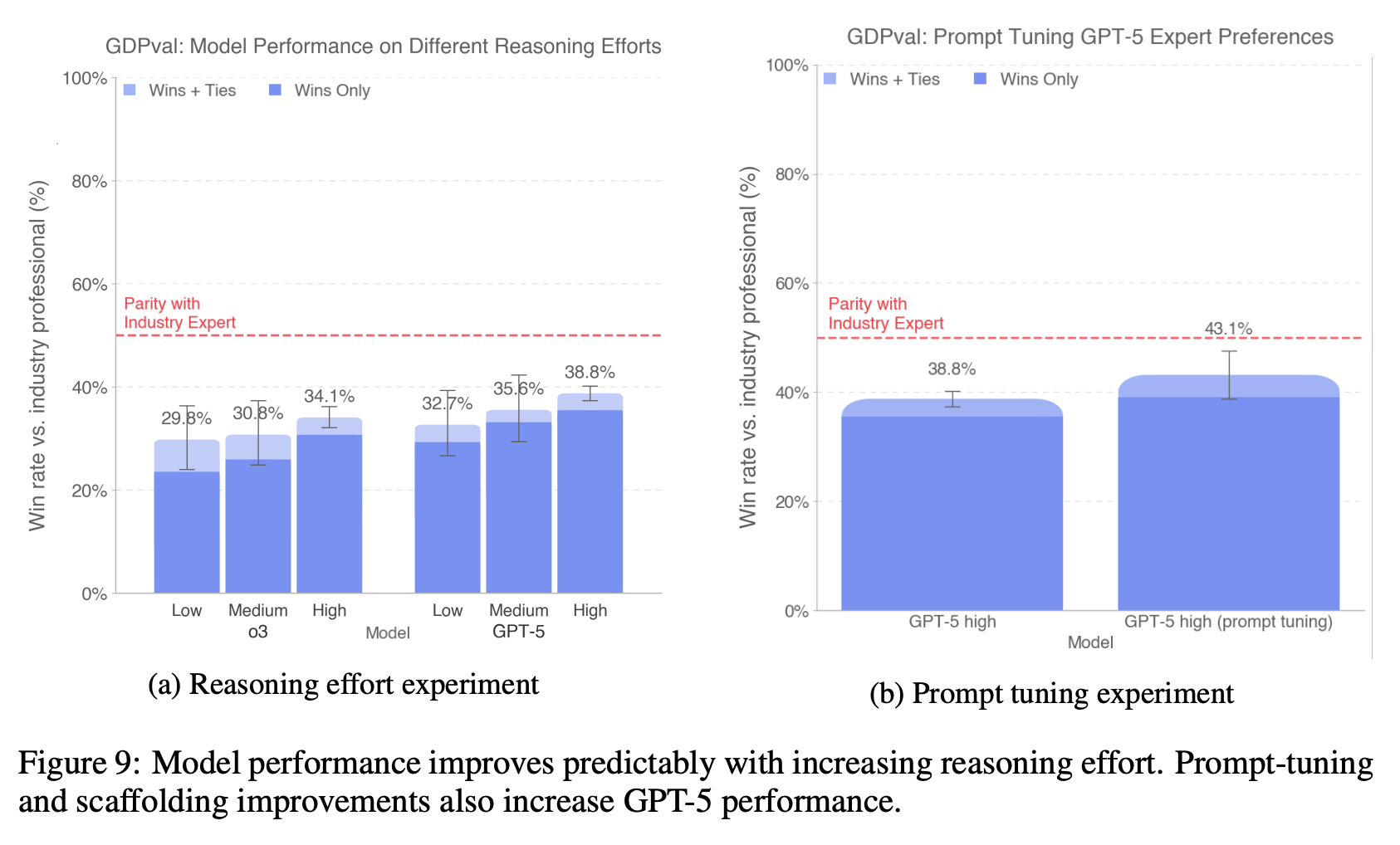
Reasoning Effort 对模型性能的影响
额外的 Reasoning Effort 能提升性能。我们对测量如何轻松提高模型能力也很感兴趣。
例如,许多观察到的 GPT-5 失败模式都是由于明显的格式错误。我们创建了一个提示,鼓励 GPT-5 严格检查交付物是否正确,通过将文件渲染为图像来检查布局,避免非标准 Unicode 字符,并避免过多的冗余。该提示适用于多模态经济任务,并没有针对任何特定问题过度拟合。
我们还通过在容器中启用 GET 请求并使用 N=4 和 GPT-5 评委进行最佳 N 采样来改进了代理框架。
提示词完全消除了 GPT-5 响应中的黑方块伪影,这些伪影之前影响了超过一半的生成 PDF 文件,并将 PowerPoint 文件中的严重格式错误率从 86% 降低至 64%。这在一定程度上归因于使用多模态能力检查交付成果的代理数量急剧增加(15% → 97%)。提示词还通过人类偏好胜率提高了 5 个百分点。
这些简单的性能提升表明,通过训练或引导代理更加细致地工作并充分利用其多模态能力,可以在 GDPval 任务中找到改进代理性能的途径。
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!