ClawGym: Part I - ClawGym-SynData
- ClawGym-SynData: 13.5K 角色驱动意图 + 基于 Skill 的操作,配备真实模拟工作空间和混合验证机制
- ClawGym-Agents:在 black-box rollout 轨迹上 SFT,之后通过一个轻量级的管道探索强化学习,该管道可在每个任务的沙盒中并行化 rollouts
- ClawGym-Bench:200 个测试实例
Intro
Claw-style 任务与 text-based tasks 以及 structured agent benchmarks 的区别与挑战:
- 需要捕捉不同职业与日常安排中的个性化需求,难以确定充分的代表性任务,从而覆盖广泛的真实场景
- 长程任务本质涉及:文件操作、工具调用、工作空间更新和中间验证;以及自动化评估的可验证性
- 根植于本地工作空间,需要现实的模拟工作空间及任务特定的工件,提供有意义的执行上下文
⇒ 开发系统化的框架,支持 agent 在 Claw-Style 环境中的训练及更广泛的 benchmark 构建
ClawGym:data-centric framework 用于统一开发 Claw-style personal agent 中的数据合成、agent 训练和性能评估
方法核心:dual-route data synthesis 生成多样和可验证的任务
具体做法:
- 角色驱动的 top-down pipeline 基于宏观的 user personas 和 scenario intents
- 基于 Skill 的 bottom-up pipeline 从具体的、可执行的能力中构建 multi-step workflow
- 通过生成任务特定的模拟文件和辅助资源,自动实例化基于 workspace 的环境
- 应用混合验证协议,结合判别式的 code-based checker 和基于定性 rubric 的 verifier
⇒ 在 OpenClaw 框架中合成 13.5K Claw-style tasks → ClawGym-SynData
ClawGym-Agents: 基于合成数据池,在 OpenClaw Harness 上收集过滤高质量交互轨迹,利用 SFT 和 RL 在 OpenClaw Framework 上进行训练
ClawGym-Bench: 从 ClawGym-SynData 中选择(排除用在 Training Set 中的)。选择过程:基于 rollout 的难度校准与大语言模型辅助的人工审核
Preliminary
Task Definition
Claw-style agent task:基于环境的指令执行问题
给定 agent 一个 user instruction 和一个初始化的 workspace,以及其中可用的 computer tools 来满足用户需求:
$$\tau = \langle\, p,\, s_0,\, \mathcal{A},\, \mathcal{F},\, \mathcal{V}_\tau \,\rangle$$- $p$:user instruction
- $s_0$:workspace 初始状态
- $\mathcal{A}$:agent 的可用动作集合
- $\mathcal{F}$:描述 tool 执行如何更新环境状态
- $\mathcal{V}_\tau$:任务特定的 verifier
输入:用户指令 $p$ + 初始环境状态 $s_0$
- 指令 $p$:描述用户目标,例如组织文件、抽取信息、编辑文档、生成报告或配置软件
- 环境状态 $s_0$:为任务提供具体的 workspace。包括本地文件和文件夹,可访问网络的接口,配置文件和其他工件
输出:agent 产生一个由 action 和 observation 片段组成的 trajectory
$$\xi = (A_1, O_1, A_2, O_2, \ldots, A_K, O_K)$$其中每个 action $A_k = (a_{k,1}, \ldots, a_{k,m_k})$ 包含一个或多个连续动作 $a_{k,i} \in \mathcal{A}$;每个 observation $O_k = (o_{k,1}, \ldots, o_{k,n_k})$ 包含一个或多个环境观测
segment-level ⇒ 非交替式的交互模式,agent 在收到或处理对应的反馈前可能发出多个 tool calls
标准严格的交替式 action-observation:$m_k = n_k = 1$ for all $k$
$(a_1, \ldots, a_H)$ 表示 $\xi$ 中可执行动作的扁平序列,其中 $H = \sum_{k=1}^K m_k$,在每个可执行动作后,workspace 状态进行更新
$$s_t = \mathcal{F}(s_{t-1}, a_t), \quad t = 1, \ldots, H$$执行 $H$ 个可执行动作后,agent 达到一个最终的环境状态 $s_H$;同时返回一个自然语言反馈 $y$,例如一份完成确认、进度总结或失败解释
Claw-style agent tasks 的主要输出是最终的环境状态 $s_H$,而非仅仅为最终的文本反馈。最终环境可能包含:新创建的文件,修改后的文档,重新组织的目录,生成的报告,其他持久化的 workspace 改变
验证标准 Verification Criteria:任务被成功完成,即最终的环境状态满足用户的初始指令
给定初始状态 $s_0$,最终状态 $s_H$,可选的最终回复 $y$,任务特定的 verifier 会分配一个分数:
$$v = \mathcal{V}_\tau(s_0, s_H, y), \quad v \in [0, 1]$$关注最终状态的正确性。$\mathcal{V}_\tau$ 被实例化为 code-based 或 rubric-based verifier:
- Code-based checker:审查判别式的工作空间属性,例如所需文件是否存在,输出 schema 是否有效,计算数值是否正确,生成的内容是否满足任务特定约束
- Rubric-based verifier:评估难以用可执行代码捕捉的定性方面,如清晰度、完整性、实用性、忠实度以及与用户意图的一致性
ClawGym-SynData
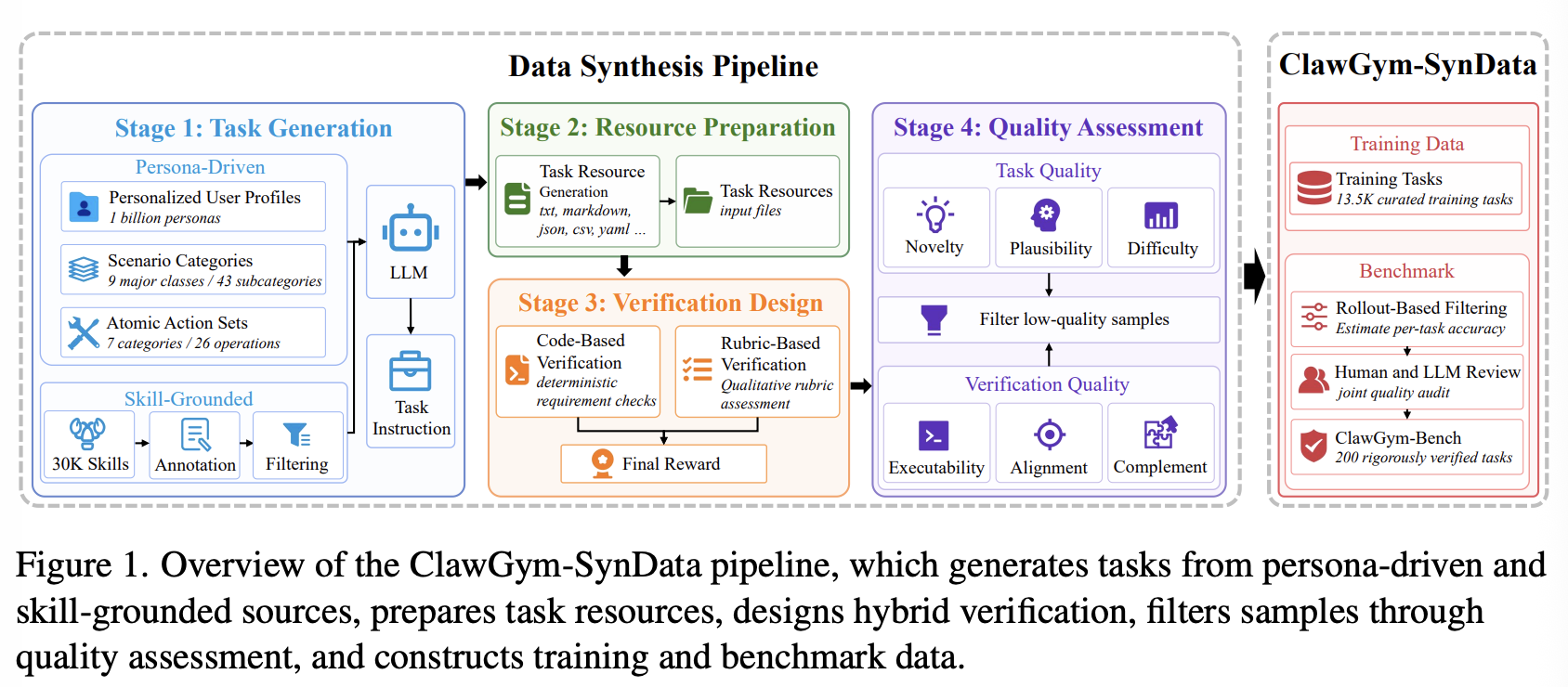
目标为 Claw agents 产生可扩展、高质量的训练数据,主要包含四个阶段:
- Task Generation:1)persona-driven top-down synthesis,基于多样化的用户场景产生任务;2)skill-grounded bottom-up synthesis,将单个 OpenClaw skill 组合形成现实、多步骤的 workflow
- Resource Preparation:创建完成任务所需的轻量级辅助文件和 workspace 工件
- Verification Design:生成 code-based 和 rubric-based checks
- Automated Quality Assessment:评估任务和验证质量
Task Generation
Persona-Driven Top-Down Synthesis
构建 task seeds:合成个性化 user 配置,场景分类和原子动作集合,指定用户是谁、该任务属于什么场景、agent 可能需要执行的操作
$$z = (u, c, \mathcal{G})$$- $u \in \mathcal{U}$: user persona,指定目标用户背景,包括 user goal,preferences 和 working context。从收集到的多样的用户配置中采样,覆盖不同的职业、工作流、偏好和日常需求
- $c \in \mathcal{C}$: scenario category。包含 9 个主要类别和 43 个子类,每个 task seed 选择一个
- $\mathcal{G} = \{g_1, g_2, \ldots, g_n\}$: basic operations,生成的指令会涉及到的操作。包含 7 种 26 个不同的操作,覆盖有代表性的 Claw-style 活动,例如网络信息检索、文件处理、文档编辑、数据分析、脚本执行、结果报告等
top-down:任务首先通过生成用户情境,然后进行实例化并添加细节,逐步进行情境化
Seed-Guided Task Instruction Generation:使用 task seed $z$ 实例化一个任务生成 prompt 模版。给定 $z$,基于 prompt template $\pi(\cdot)$,利用 task generator $\mathcal{M}_{task}$ 生成面向用户的任务指令
$$p = \mathcal{M}_{task}(\pi(z))$$$p$:任务定义中的 instruction,指定 user goal,context,expected operations 和 output requirements。反映了 top-down 的任务构造本质:persona $u$ 和 scenario category $c$ 决定任务方向,选择的基础操作 $\mathcal{G}$ 将 instruction 约束到合理的 workspace operations
Skill-Grounded Bottom-Up Synthesis
从 OpenClaw skills 已经实现的具体能力出发。从 ClawHub 收集原始 Skill,每个 Skill 被组织成一个包含 SKILL.md, README.md 或其他使用说明的文件夹。每个 Skill 被视为一个可重复的能力单元目标服务于构建基于环境的 workflows
目标:识别适合任务合成的技能,规范能力描述,组合成实际的任务说明
Skill Annotation and Filtering:给定原始 skill 集合 $\mathcal{K} = \{k_i\}_{i=1}^N$,用 LLM 将每个 Skill 转化为一个结构化 Skill 注释 $\mathcal{M}_{ann}$,即
$$\alpha_i = \mathcal{M}_{ann}(\rho(k_i))$$其中 $\rho(\cdot)$ 是标注 prompt;$\alpha_i$ 总结了任务合成所需的关键信息,包括 Skill 的 summary, core content, usage constraints, 输入输出特征, 二元可合成标签 $y_i \in \{0, 1\}$
- $y_i = 1$ ⇒ 该 Skill 能进行可靠的任务合成
- $y_i = 0$ ⇒ 应该被过滤,例如依赖于无法使用的 credentials、缺乏充分的任务相关的细节、与目标任务格式不兼容
保留可合成的 Skill:$\mathcal{K}^+ = \{(k_i, \alpha_i) \mid k_i \in \mathcal{K},\, y_i = 1\}$
两个目标:1)过滤在目标设置下不适合合成可靠任务的 skill;2)为 task generator 提供规范化的能力描述
⇒ 标注 30K 原始 OpenClaw Skills,保留 16K 可用 Skills
Skill-Composition Task Construction: 构建每个任务时,从一个主要的 Skill 出发,再随机采样一些 supporting skills。主要的 Skill 定义核心能力和主要任务目标,supporting Skill 引入辅助操作或 contextual requirements
每个任务使用 1 个主要的 Skill 和至多 3 个可选的 supporting Skills,被选择的 Skill bundle 技能包,提供给 generation model,生成面向用户的 task instruction
$$p = \mathcal{M}_{task}(\pi(k_{main}, \mathcal{K}_{support}))$$其中 $k_{main}$ 表示主要 Skill,$\mathcal{K}_{support}$ 表示 supporting skill set,$\pi(\cdot)$ 是任务构造的 prompt。生成的任务指令以统一的格式描述:用户需求、所需资源、期待行为、验证目标
Resource Preparation
Claw-style 任务需要具体的文件来初始化 workspace state。给定合成指令 $p$,构建 $s_0$ 中基于文件的组件
为每个任务生成定制的轻量化模拟文件,例如需要总结的文档、需要分析的表格、需要检查的配置文件、重新组织记录、限制预期输出的参考材料
识别文件需求,包括:文件名、目录地址、格式、关键领域、内容约束
$$f = \{(l_i, t_i, d_i)\}_{i=1}^m$$$l_i$ 表示文件路径,$t_i$ 表示文件类型,$d_i$ 表示文件内容规范;之后利用一个 LLM-based resource generator 将 $f$ 转化成具体的文件,放在特定的 workspace 路径下
生成的文件是任务特定以及可验证的:
- Text or Markdown:内容提供实体、约束、指令需要的参考文件
- 结构化文件 JSON, CSV, YAML:生成显示 schemas, tables, fields, values,后续 checker 可以重新计算所需的统计数据或验证输出一致性是否符合输入
⇒ 每个任务 self-contained,reproducible,consistent with verifier,避免真实用户文件隐私泄漏和不确定性
Verification Design
Claw agent 执行完一个任务后,核心挑战:判断任务是否被正确完成。任务成功依赖于生成的文件、修改的工件、数据转换、结构化输出或最后的答复 ⇒ 异质化:一些可以被判别式检查,一些需要质性判断
混合验证 scheme:code-based verification and rubric-based verification
Code-based Verification
针对可执行的客观需求,例如是否创建了所需的文件,输出是否符合指定的模式,或者计算出的值是否正确
对每一个合成任务,生成一个可执行的 checker 来验证目标需求。需求被解构为一组原子化的验证
$$\mathcal{C} = \{c_1, c_2, \ldots, c_m\}$$其中每个 $c_i$ 对应一个确定性条件,例如输出文件的存在性,JSON 字段的正确性,计算统计的有效性,生成文档中所需内容的存在性
checker 在输入资源与生成输出上进行交叉验证。给定 instruction $p$,初始和最终的 workspace 状态 $s_0, s_H$,以及可选的最终回复 $y$
$$b_i = \mathbb{I}[c_i(p, s_0, s_H, y) = \text{true}], \quad b_i \in \{0, 1\}$$ $$s_{\text{code}} = \frac{1}{m}\sum_{i=1}^m b_i$$Rubric-based Verification
评估难以形式化为确定性检查的定性要求,例如清晰度、完整性和风格。为每个任务生成一个 rubric rules set
$$\mathcal{R} = \{r_1, r_2, \ldots, r_n\}$$每个 rule 定义了一个具体的质量维度,分配一个分数
$$q_j = \text{score}_j[r_j(p, s_0, s_H, y)], \quad q_j \in \{0, 0.25, 0.5, 0.75, 1.0\}$$其中 $r_j$ 是第 $j$ 个 rubric rule,$\text{score}_j(\cdot)$ 将 verifier 的判断映射到预定义的分数分布
$$s_{\text{rubric}} = \frac{\sum_{j=1}^n w_j q_j}{\sum_{j=1}^n w_j}$$其中 $w_j$ 表示每个 rubric rule $r_j$ 的权重,默认情况下权重平均,除非需要任务特定的加权
分数聚合
最终分数取决于可获取的验证信号:
- 只有 code-based verification 的任务:$s_{\text{task}} = s_{\text{code}}$
- code-based and rubric-based verification:$s_{\text{task}} = \lambda\, s_{\text{code}} + (1-\lambda)\, s_{\text{rubric}}$
其中 $\lambda \in [0, 1]$ 控制客观与主观的相对重要性:此处设置 $\lambda = 0.7$
原因:Claw task 完成通常更依赖于具体和可重复的 workspace 改变,例如生成文件,结构化输出和数据转换
Automated Quality Assessment
自动质量审查过滤低质量的样本,评估两个维度:
- 合成任务的质量:关注任务的 reasonable, self-contained, executable, clearly specified
- 验证工件的可信度:审查生成的 code checker 和 rubric rules 是否正确和全面的判断任务完成
设计细粒度的审查程序,联合审查任务有效性和验证可靠性
Task Quality Assessment
目标:识别合成任务是否冗余、不可行、校准不良;从三个维度审查:novelty、reasonableness、difficulty ⇒ 判断任务是否添加新的 coverage,在实用的 Claw-style workspace 下执行,具有精确的复杂度
- Novelty:利用 task embeddings 间的余弦相似度判断新颖性。对新加入的生成任务,计算与当前 task pool 的最大相似度,与阈值比较判断是否保留 ⇒ 去除冗余任务模式,提升多样性
- Plausibility 可信度:使用 LLM judge 判断任务可信度,作为二元决策:判断任务是否清晰、内部一致、作为 Claw-style 用户请求的现实性。检查任务是否依赖于不可用或虚构的环境组件
- Difficulty:使用 LLM judge 估计任务难度,反映期待交付的复杂度,包括需要的步骤数、操作多样性和所需规划量或跨资源推理量
Verification Quality Assessment
负面情况:Incorrect checker(评估无效)、Overly lenient checker 过度宽松(可能奖励表面化的输出)、Overly strict checker 过度严格(可能惩罚有效解决方案)
Code-based verification:检查 checker 是否能够正常运行,覆盖核心的目标需求,避免过度宽容和严格
- Executable Sanity Check:确保 checker 语法正确,运行无错误。检查过度宽容的 checker:重新构建任务的初始 workspace,放置所需的模拟输入文件到指定的路径,但不提供任何代理生成的输出(仅仅放置表面文件,不包含具体内容)
- Task-checker Alignment Review:使用 LLM judge 从两个角度审查 checker 与任务指令和输入文件:
- Requirement Coverage:衡量 checker 是否验证了任务的核心目标要求
- Over-strictness:衡量 checker 是否强制执行超出任务规范的条件
Rubric-based verification:检查是否通过针对难以确定性验证的定性方面来补充代码检查器,而不是重复可验证的要求。使用 LLM judge 衡量生成的 rubrics 是否提供了 code checker 的补充评估信号。应更关注质性角度,例如 tone, clarity, organization, faithfulness, completeness of explanation
Synthesized Task Analysis
Persona-Driven and Skill-Grounded Task Distribution
Persona-Driven 合成数据分布:覆盖了广泛的用户场景,没有任何一个类别占据主导地位;即使是最大的类别也只占任务总数的 12.5%。原子操作分布还显示了多种可执行操作,包括信息获取、工作区检查、数据提取、计算、消息草拟和报告编写
⇒ Persona-Driven 合成产生的任务在场景覆盖和所需操作方面都具有多样性
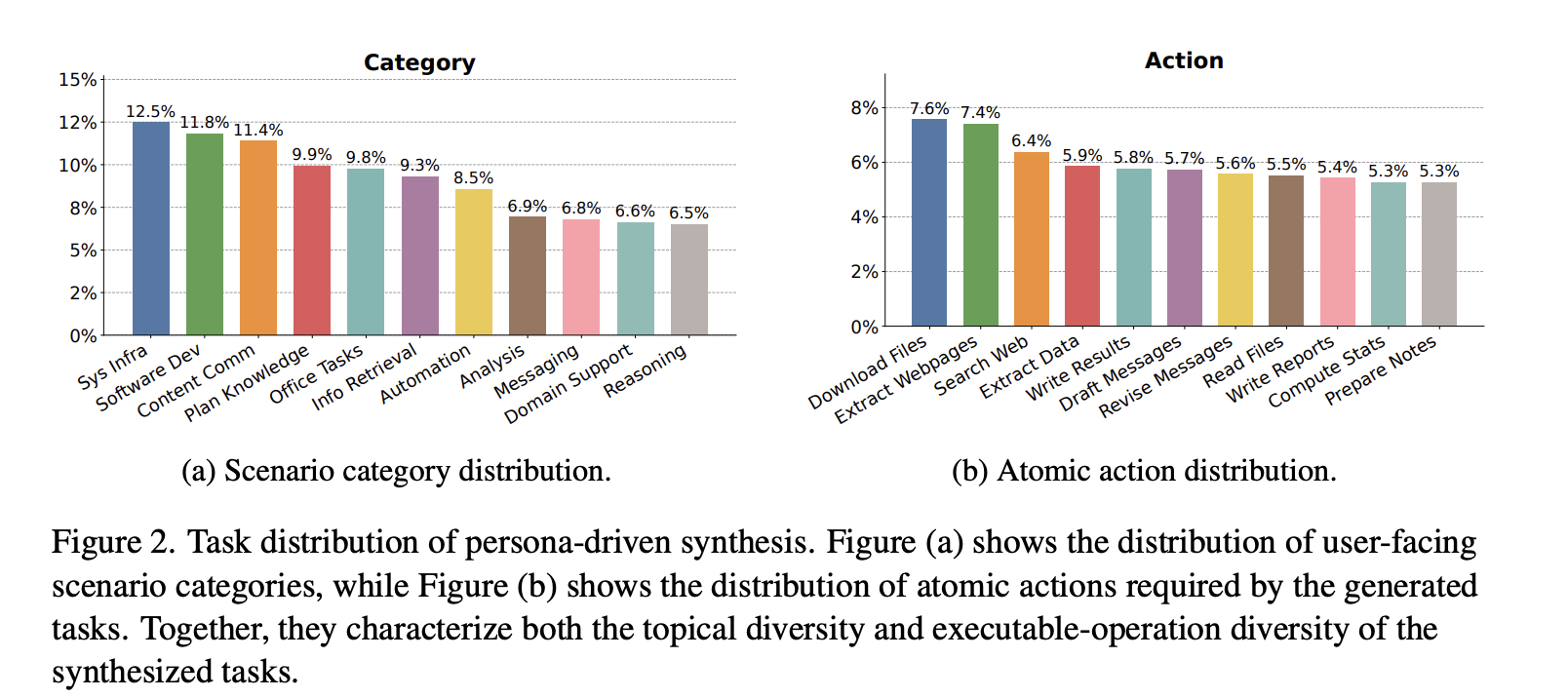
Skill-Grounded 合成数据分布:分析 16K 可用 Skill。这些技能涵盖多种能力类别,其中数据与 API 以及开发工具占最大比例,其次是工作流、自动化、安全、提示和 MCP 工具
Skill-Grounded 合成是建立在一个广泛的可执行能力空间上,而不是一个狭窄的操作集合上

两种方式存在协同效应:Persona-Driven 合成扩展用户场景多样性,Skill-Grounded 利用可重用的 Skills 强化操作基础
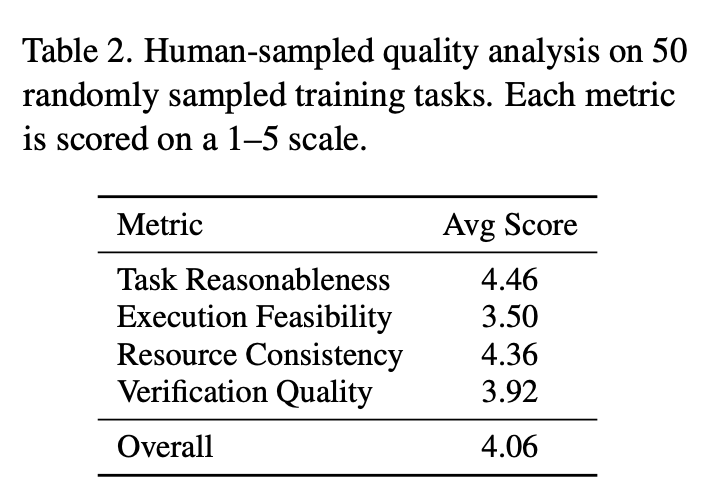
Human-Sampled Task Quality Analysis
随机采样 50 个任务实例进行 human evaluation,沿 4 个维度:task reasonableness, execution feasibility, resource consistency, verification quality,每个维度打 1-5 分
Reference
[1] ClawGym: A Scalable Framework for Building Effective Claw Agents
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!