ClawGym: Part II - ClawGym-Agents and Bench
ClawGym-Agent
Black-Box Rollout
传统的 agentic training 依赖于显式的 agent loops,以预定义格式的方式控制 agent-environment interaction。OpenClaw 等框架更高度封装 ⇒ 内部的执行细节,如 context 管理和 subagent 会话是完全不透明的
为收集 OpenClaw 轨迹,采用 black-box rollout 策略,直接利用 OpenClaw 的 Harness;而非使用单独的 agent loop 或者构建额外的 harness 来近似 OpenClaw 的交互协议,包括 OpenClaw 的原始控制流、tool 接口、agent-environment 交互语义
具体做法:在一个分布式集群上部署多个 OpenClaw Docker 环境,将每一个实例视作一个可执行的黑盒系统。对于每个合成任务,给每个指定的 Docker 容器分配任务描述和对应的 workspace 材料
执行过程中,OpenClaw 控制 agent 通过 tool call 和 textual observation 与本地环境进行交互
引入一个 proxy layer,记录 rollout 中每个 request 和 response,来记录这些交互而不改变 agent 逻辑。该 proxy 可以捕获完整的多轮交互流,包括模型输入输出,tool 调用和环境反馈
⇒ 获得 OpenClaw rollout 轨迹,能够忠实地反映 agent 在真实的本地环境中如何解决任务
Trajectory Aggregation and Selection
将原始交互记录聚合为完整的 trajectory。proxy 记录的是单个模型的调用,一个任务执行可能对应多个请求,这些请求间可能存在部分重合
通过聚合共享同一个 message 前缀的请求,连接上后续的交互,从而从碎片化的 OpenClaw 日志中恢复多轮轨迹
实践中可以观察到,长时间运行的 OpenClaw 会话,会显式地在对话中插入系统级的辅助 prompt,例如 cron message 或 heartbeat message
这些辅助 prompt 的作用:维持会话活动或启动次要的交互分支,但它们并不直接有助于解决目标任务 ⇒ 在聚合过程中,需要移除这些系统级的辅助 prompt,仅仅保留与任务执行相关的交互片段
同时过滤涉及 unsupported tools 的轨迹:例如 canvas-related 操作在远程部署中不可用,且不是合成任务所必需的 ⇒ 避免虚假的工具调用失败将不必要的噪声引入训练数据
基于 verifier 分数进行 trajectory 选择。采用基于奖励阈值过滤的方法:确保轨迹对应一个有效且完整的交互过程后,仅保留最终得分超过预定义的奖励阈值的数据进行训练 ⇒ 24.5K 高质量交互数据用于 SFT

每个轨迹包含平均 13 轮交互和平均 18.67K tokens,保留的数据包括非平凡的多次执行,而不是简短的单一回合响应。包含平均 15.82 个 tool calls 和平均 3.25 种 tool 类型,在多种操作类型之间进行频繁的工作空间互动和协调
Agentic Training for Claw Agents
在 Qwen3 (Qwen3-4B-2507-Instruct, Qwen3-8B, Qwen3-30B-A3B-2507-Instruct) 上进行多轮 SFT
Claw tasks 经常需要与本地文件、工具和环境反馈进行多次长程交互,轨迹长度可能会超过标准指令微调的长度。Qwen3-8B:原生上下文窗口 32K,使用 YaRN 延长至 64K
训练过程中,采用针对 agent 交互数据的 multi-turn loss masking strategy,即 Docker-based execution 产生的环境反馈 token 被排除在 loss 外
优化目标在模型生成的轨迹部分,包括:reasoning, decision making, tool-call generation
⇒ 获得 ClawGym-Agents,包括 ClawGym-4B, ClawGym-8B, ClawGym-30B-A3B
RL with Sandbox-Parallel Rollouts
将每个 OpenClaw agent loop 作为黑盒,每个任务虚拟化到独立的 sandbox 中,包括其 root filesystem, workspace, gateway, verifier
包含 3 个优势:
- Sandbox-Parallel Rollout:允许多个任务 rollouts 同时运行而不相互干扰
- Low Infrastructure Dependency:适用于不同集群设置的可互换的基于 Docker 和无 Docker 沙箱后端
- Outcome-Reward-Only Training:code checker 直接提供奖励信号,避免使用辅助奖励模型或过程级监督
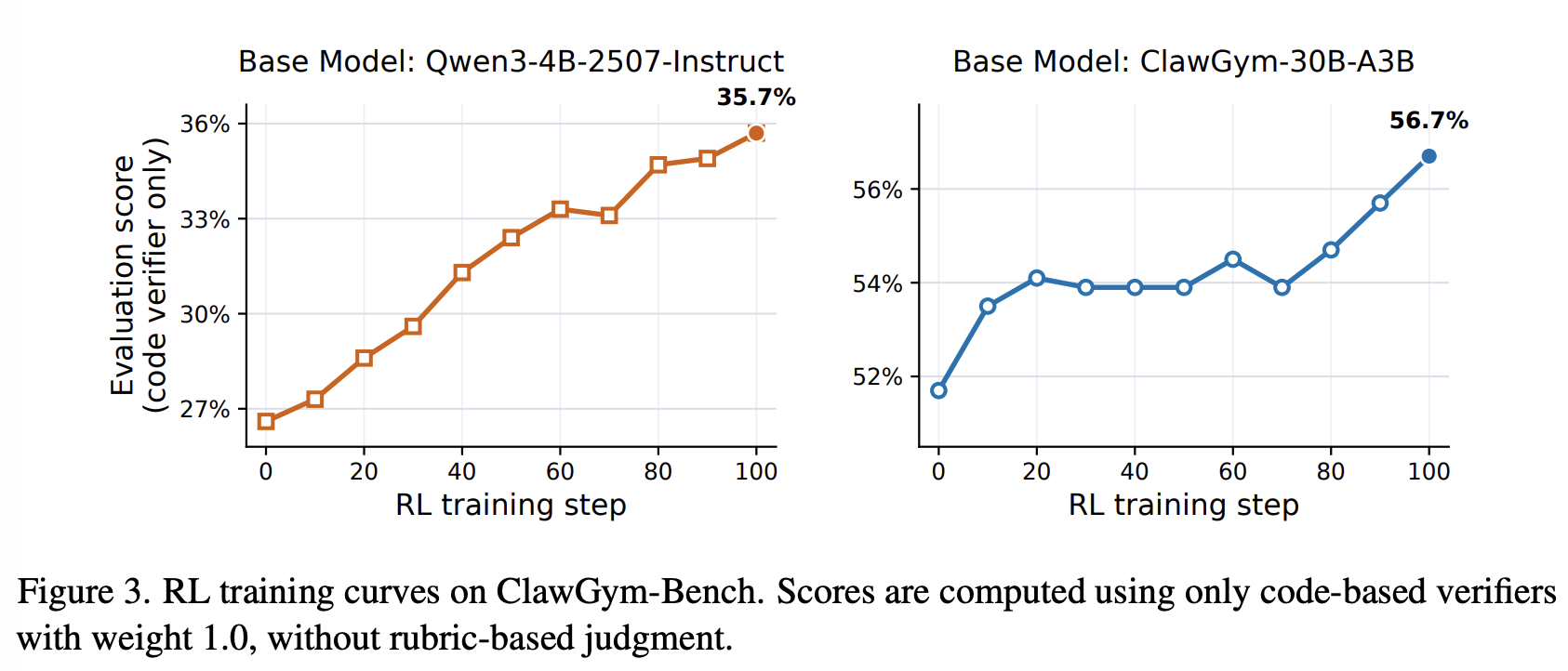
ClawGym-Bench
从合成 task pool 中利用一个严谨设计的多阶段选择过程来构建 ClawGym-Bench,目标:减少噪声样本,产生可靠的基于 workspace 任务的 Benchmark,包括文件操作、数据处理、文档编辑、代码执行和其他现实的 computer-use workflows
Benchmark Construction
使用更严格的构造过程,关注:难度校准、验证器可信度、基于 workspace 场景的多样性覆盖程度
Difficulty-Aware Filtering
使用 $\mathcal{D}_\text{cand}$ 表示经过任务质量和验证器质量过滤后保留的合成任务集合,使用 rollout-based 难度过滤选择更合适的 benchmark 样本
对于每个 task $\tau \in \mathcal{D}_\text{cand}$,使用一个 strong LLM agent 和一个 smaller LLM agent 分别执行 $n=4$ rollouts,计算其平均完成分数 $\bar{s}_\text{strong}(\tau)$ 和 $\bar{s}_\text{small}(\tau)$
这些分数反映:任务是否可解决、是否过于简单、是否可以区分 agent 的不同的能力,具体标准:
$$ \begin{cases} \bar{s}_\text{strong}(\tau) \ge 0.2,\\ \bar{s}_\text{small}(\tau) \le 0.6,\\ \bar{s}_\text{strong}(\tau) > \bar{s}_\text{small}(\tau) \end{cases} $$- 移除太困难或对 strong agent 都不稳定的任务
- 过滤对 smaller agent 已经足够简单的任务
- 保留能够反映有意义的能力 gap 的任务
LLM-Assisted Human Review
保留的候选需要经历一个 human-LLM 协作审查才能加入 Benchmark。使用 frontier LLM 进行详细诊断,检查 task instruction, input files, code checker, rubric rules,之后报告潜在的问题和具体修改建议
⇒ 关注任务是否清晰和可行,输入资源是否支撑目标任务,checker 是否可执行和适当严格,rubric 是否是对 code verification 的补充
Human Reviewers 作出最终决策,检查 LLM feedback,决定识别到的问题是否有效,是否接受、修正或拒绝候选,必要时增加缺少的细节
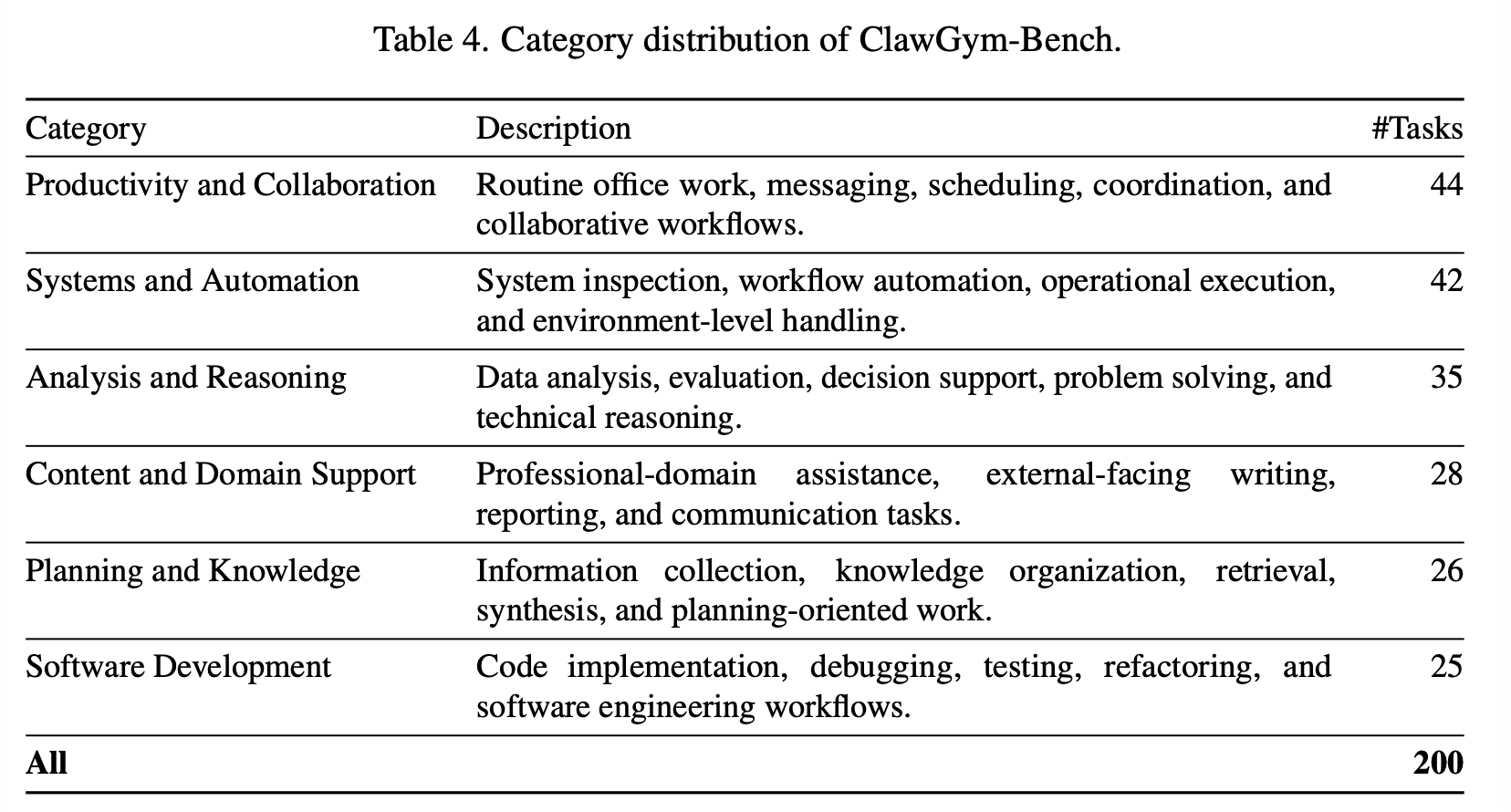
Benchmark Composition
包含 200 tasks,每个实例包含一个 user instruction, 任务特定的模拟 resources, 对应的 verifier。其中 156 个只使用 code-based checkers,44 个使用混合评估
包含 6 个 task 分类,下面是分类定义和比例:
Evaluation Protocol
在 harness-based workspace setting 下评估:每个任务用对应的模拟资源进行初始化,agent 和 workspace 进行交互,最终状态使用对应的 verifier 进行打分
Evaluation Stability
Claw 评估涉及在 harness 上的多轮交互、长执行 context,频繁的 tool call。在一个 50 个任务的固定子集上测试不同大小模型的稳定性,根据类别均匀采样
每个模型在同样的 harness 上评估 5 次,使用同样的 workspace 初始化、模拟资源和验证器。标准差很小($\le 1\%$),表示 ClawGym-Bench 可以支持可靠的模型比较,而无需更多的重复测试来消除随机性

Verifiable Solvability
每个任务被检查确保至少存在一条可行路径,确保每个任务能够通过人工参考的方式获得满分。保证 ClawGym-Bench 反映的是被评估的 agent 的缺陷而非不可行的任务设计、无效的输入文件或不可验证的工件
Experiment
Results
- ClawGym-SynData 能否提升开源模型,缩小其与 stronger agents 间差距
- ClawGym-Bench 是否在不同模型规模和任务类别上提供了足够有区别的评估
- ClawGym-Agents 在 PinchBench 这个外部 Benchmark 上测试,判断其泛化性
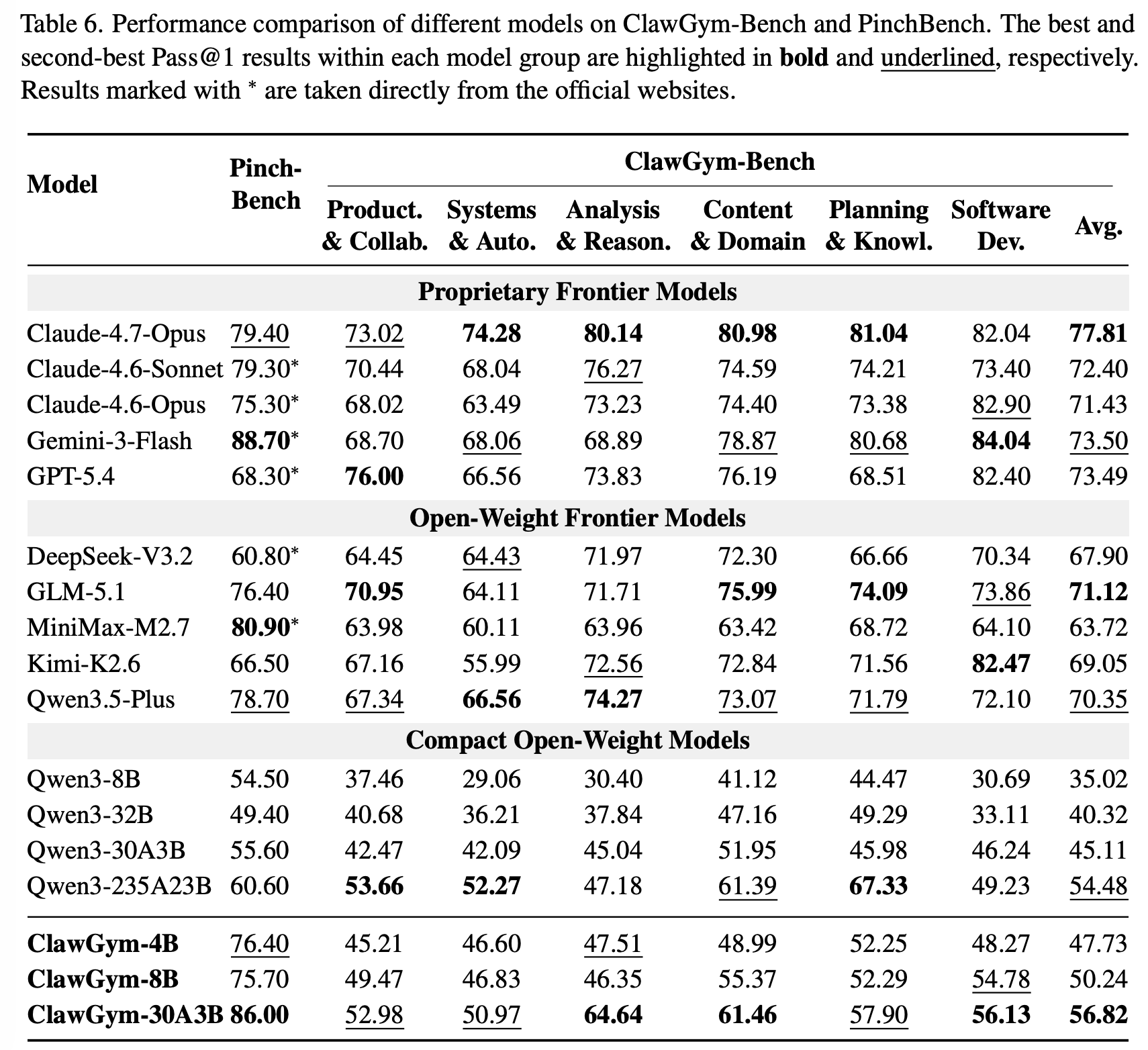
合成数据有效性:在合成数据上进行训练,能够有效提升开源模型性能。ClawGym-Agent 能超过对应的 base model,在 PinchBench 上 ClawGym-30A3B 甚至能与专有模型有竞争力
ClawGym-Bench 的判别能力:从任务分类和模型能力角度提供了判别信号。
- 任务分类:没有 agent 在所有维度都最好。其中 Claude-4.7-Opus 达到最高平均分,GPT-5.4 在 Product. & Collab. 上表现最好,Gemini-3-Flash 在 Software Dev. 上表现最好
- 模型层面:从 Qwen3-8B 35.02 分到 Claude-4.7-Opus 77.81 分,能够区分不同模型能力粒度
超越合成场景的泛化能力:ClawGym-Agent 完全在 ClawGym-SynData 上监督训练,其在外部 Benchmark PinchBench 上的性能说明 ClawGym 的强泛化能力。模型内化了核心功能逻辑,而非在 ClawGym-SynData 上过拟合
Analysis
合成策略的协同作用
目标:验证 persona-driven top-down synthesis 和 skill-grounded bottom-up synthesis 的必要性,在不同任务来源的轨迹数据上进行训练
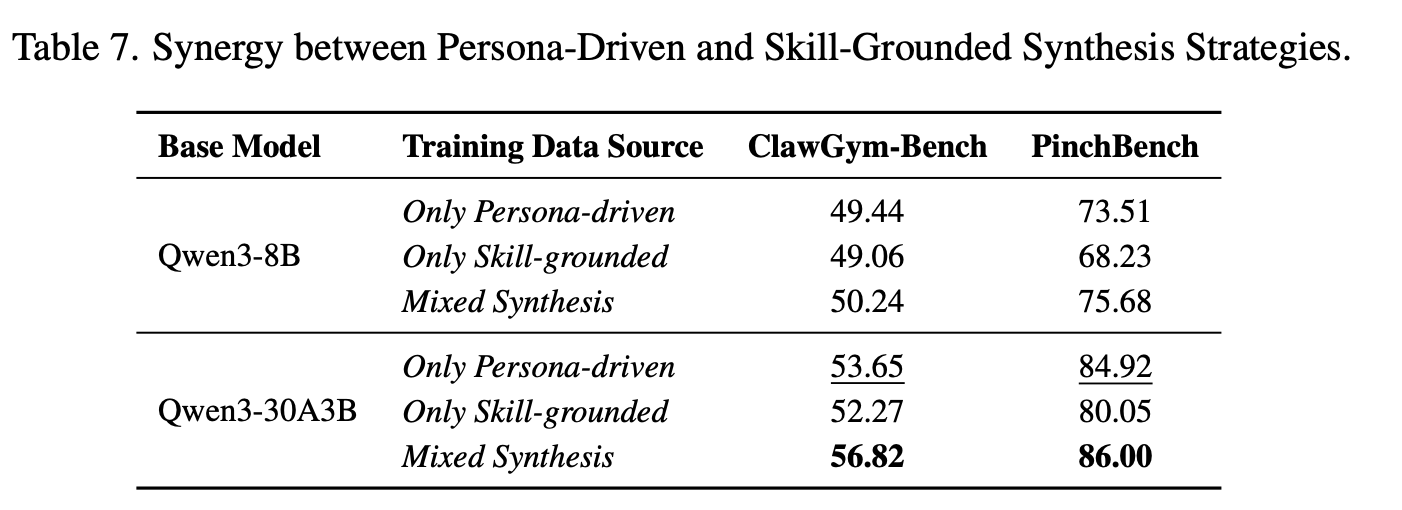
在混合合成数据上训练的模型强于单一策略的模型。Persona-Driven 策略保证了真实用户场景的全面性,Skill-Grounded 策略将任务锚定在 agent 的实际功能边界 ⇒ 链接抽象用户需求和具体工具调用
训练策略和收敛
研究 training exposure 训练暴露量对模型的影响,分析了 5 epochs (103 steps per epoch) 的 training dynamics,每 60 steps 评估 ckpt
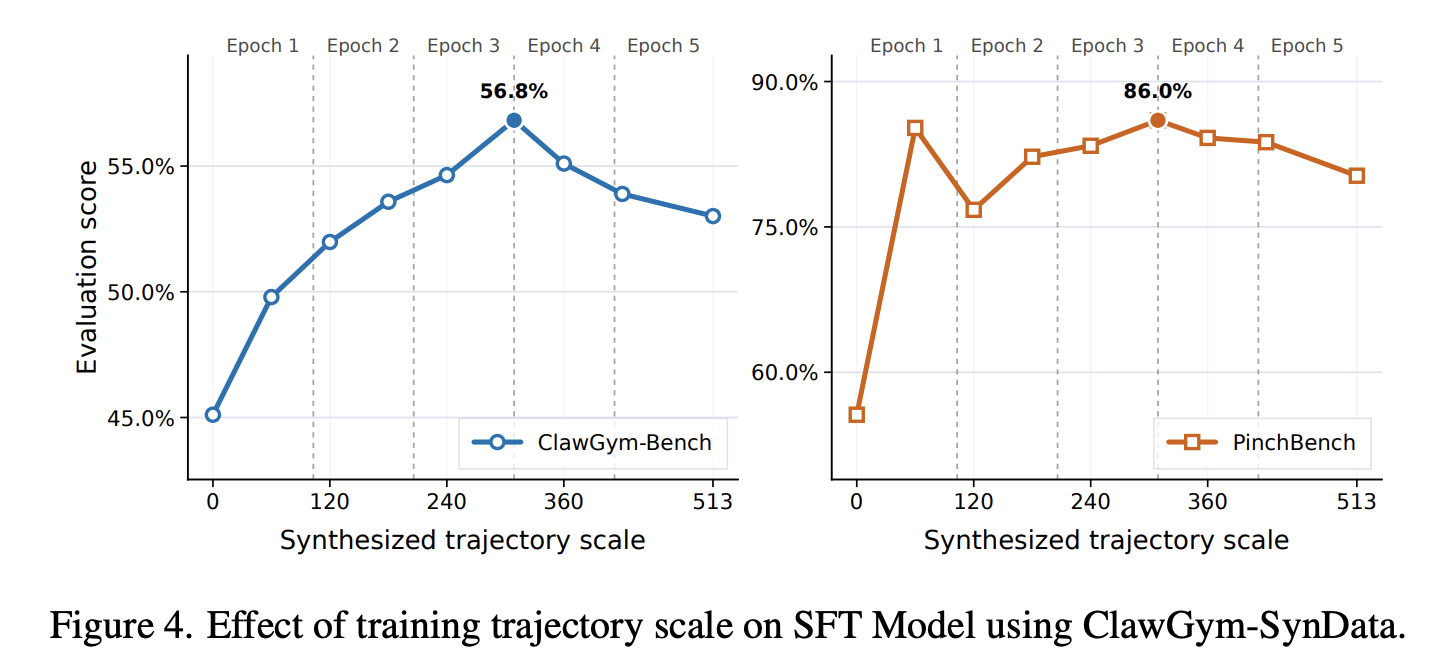
在 base model (step 0) 上收益最大,验证了合成轨迹的高质量。Performance peaks 在第三个 epoch (step 309) 之后观察到轻微但稳定的下降 ⇒ 确定最佳训练规模至关重要,初始曝光使模型能够有效地内化特定 agent 能力,过多的迭代会导致在合成数据分布上的边际过拟合
Reward 阈值的影响
目前 agentic training 轨迹数据的选择基于简单的 reward-based threshold 策略 ⇒ 阈值的选择会控制任务完成保真度和数据覆盖度间的 trade-off
为识别最优阈值,在 0.4-0.9 间进行评估,0.5 的阈值能够产生最好的结果,标志着执行完整性与数据多样性的关键平衡点
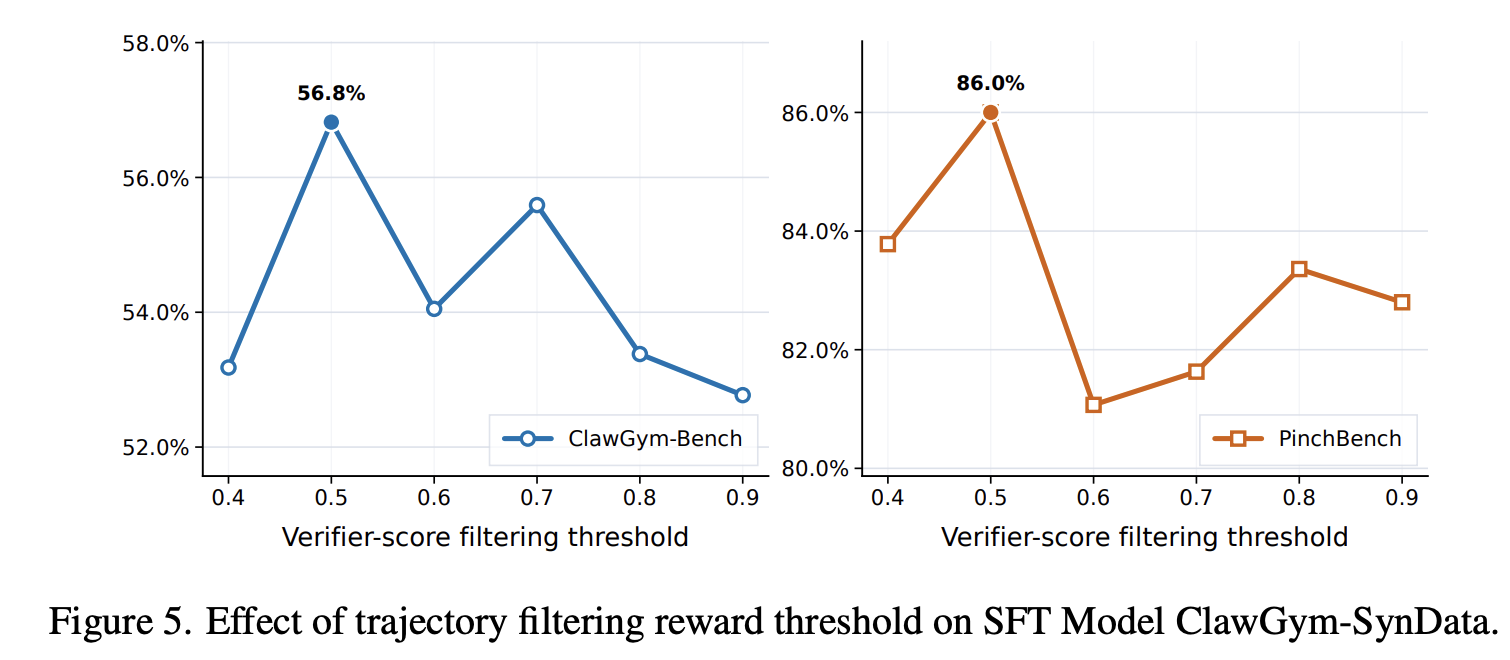
更低的阈值引入任务完成不足的轨迹,可能会降低监督信号;更高的阈值,会修剪有价值的行为多样性:过于严格的过滤可能会丢弃那些,尽管完成度评分不完美,但表现出关键恢复模式或复杂、异质任务的局部策略的轨迹
Behavioral Analysis
Claw-Style 任务需要 agent 使用本地文件和工具,处理执行反馈,更新持久化的 workspace,涉及适当的 tool-use, long-horizon execution robustness, 细粒度的指令遵循 ⇒ 对比 GPT-5.4 和 Qwen3-30B-A3B 的 case
Tool-Use Appropriateness
更强的轨迹扩展了文件模式,检查了 JSON schema,使用一个 Python 聚合脚本来计算 reports,形成一个发现-检查-计算验证流程
较弱的轨迹通过使用 find 和读取匹配的文件从无效通配符读取中 recovery,但是没有将这个 recovery 转化为可靠的计算过程,其输出在摘要字段、分组计数、过滤语义和关键实例检查方面仍然脆弱
⇒ tool-use appropriateness 超越了选择有效的工具:可靠的 agent 必须组合探索、计算、反馈和验证来达到最终目标

Long-Horizon Execution Robustness
Long-Horizon 任务要求 agent 协调许多依赖步骤,包括读取文件、运行脚本、生成工件、检查中间输出以及跨重跑保留工作区状态
Robustness 不是每个 action 从一开始就正确,而是 agent 是否可以解释反馈,从中断中恢复,继续沿着有效的 solution path 而不丢失 task context ⇒ 早期故障会影响后续工作内容和最终 workspace 状态
GPT-5.4:遇到缺失的可选内存文件,将其视为非阻塞,并继续检查收件箱文件;命令被拒绝后,会避免重复失败操作,重新设置相关状态文件
Qwen3-30B-A3B:会累积未解决的错误,陷入与审批相关的死胡同,导致所需的状态未完成

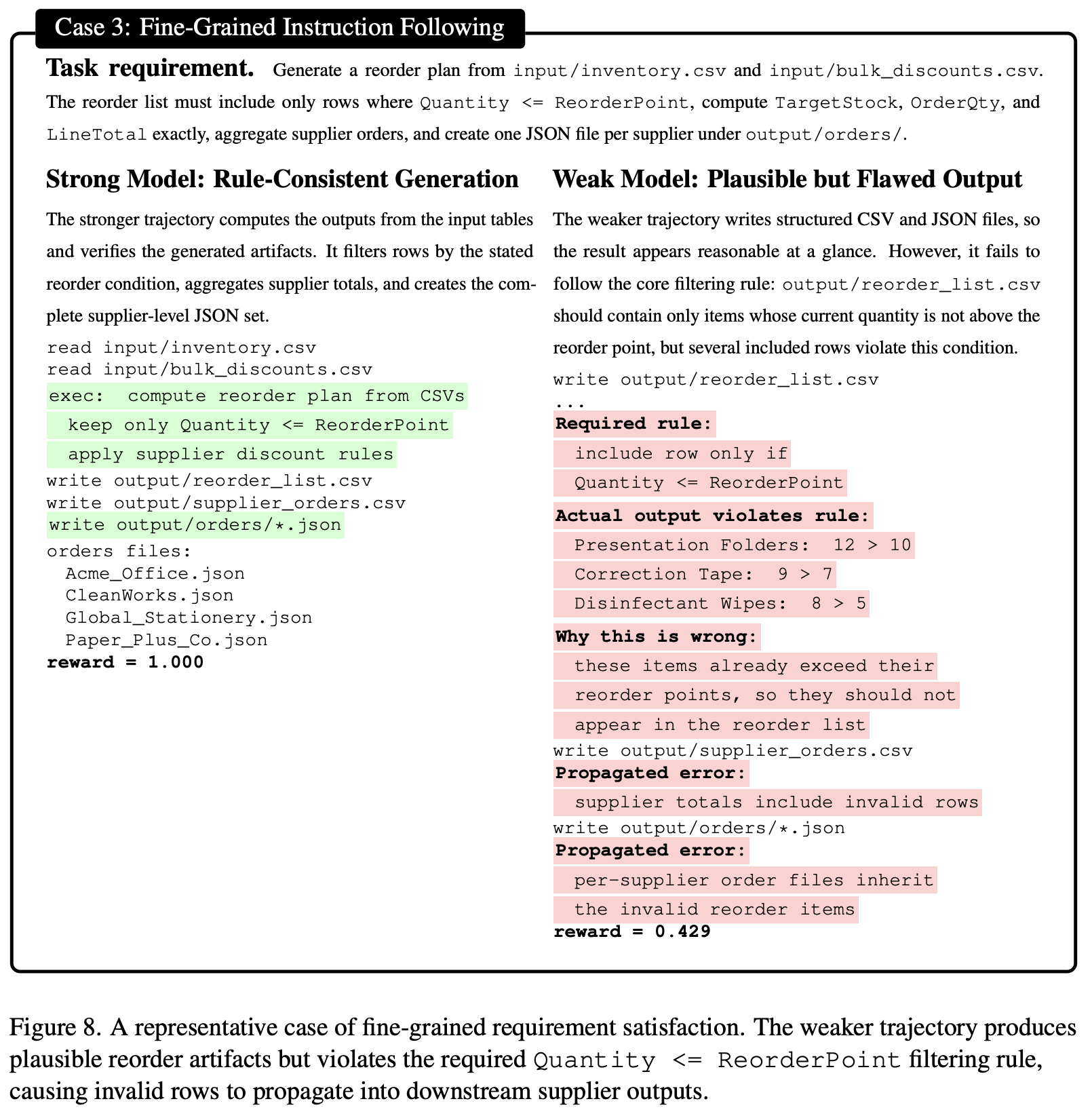
细粒度指令遵循
Claw-Style 任务通常包含一些小但重要的约束,包括过滤规则、输出模式、数值公式和跨文件一致性要求
GPT-5.4:一开始应用所需条件 Quantity ≤ ReorderPoint,之后基于过滤的记录计算下游供应商输出
Qwen3-30B-A3B:生成合理的 CSV 和 JSON 文件,但包含不符合所需条件的无效项目
Reference
[1] ClawGym: A Scalable Framework for Building Effective Claw Agents
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!