OpenSeeker:完全开源训练数据,学术团队实现前沿级搜索 Agent
Motivation:搜索 Agent 的"数据护城河"困境
在过去的一年中,深度搜索(Deep Search)能力已经成为前沿大语言模型(LLM)Agent 不可或缺的核心竞争力。截至 2026 年 3 月,已有超过十个 Agent 系统在代表性基准 BrowseComp 上突破 50 分大关,标志着自主网络智能进入新时代。
然而,这一飞速进展的背后隐藏着一个令人担忧的现实:高性能搜索 Agent 的训练一直被资金雄厚的企业巨头所垄断。最强大的搜索 Agent 目前由 Google、OpenAI 等公司的专有模型主导。虽然 Kimi、MiniMax 等实验室贡献了开源权重模型,但它们对训练数据始终保持沉默。即使在学术界,现有工作要么只开源模型不开源数据,要么仅提供小部分数据,要么数据质量不足以达到有竞争力的性能。
核心困境:高质量训练数据的持续缺乏,已经严重扼制了开源社区在搜索 Agent 领域近一年的发展。企业凭借"数据护城河"将前沿性能保持为商业机密,学术界和开源社区长期缺乏训练高性能 Agent 所需的 完全开源、高质量的训练数据。
为此,来自上海交通大学的纯学术团队提出了 OpenSeeker——首个实现前沿级性能且完全开源训练数据的搜索 Agent。OpenSeeker 不仅是一个开源权重的模型,更是对搜索 Agent 全流程的民主化:同时开源完整的训练数据集(包括复杂问答对和详细交互轨迹)与模型权重。

值得注意的是,OpenSeeker 仅使用 11.7K 合成样本通过简单的 SFT(Supervised Fine-Tuning,监督微调)进行单次训练(无超参调优、无启发式过滤),即在 BrowseComp(29.5%)、BrowseComp-ZH(48.4%)、xbench-DeepSearch(74.0%)和 WideSearch(59.4% item F1)等基准上达到最先进水平,甚至超越了通过大量持续预训练+SFT+RL 训练的工业界模型(如通义 DeepResearch 在 BrowseComp-ZH 上的 46.7%)。
方法总览
OpenSeeker 的高保真数据背后,由两项核心技术驱动:
① 基于事实的可扩展可控 QA 合成(Fact-Grounded Scalable Controllable QA Synthesis):从真实网络图谱中逆向构建复杂的多跳推理问题,确保问题具有可控的覆盖范围和复杂度。
② 去噪轨迹合成(Denoised Trajectory Synthesis):通过回顾式摘要机制为教师模型生成去噪后的上下文,促使其产生高质量动作;同时让学生模型在原始噪声轨迹上进行训练,迫使其内化去噪和信息提取能力。
QA 合成:从网络图谱到复杂推理问题
传统的 QA 合成方法往往依赖于 LLM 自由生成问题-答案对,存在两大缺陷:(1) 容易产生幻觉,不可靠;(2) 难以控制问题的推理复杂度和多跳性质。OpenSeeker 提出了一种全新的范式——从真实网络图谱中逆向构建推理路径,再将其转化为强制多跳推理的问题。

第一步:图扩展(Graph Expansion)
将网络建模为一个有向图 \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\),其中 \(\mathcal{V}\) 表示网页节点,\(\mathcal{E}\) 表示超链接边。从一个随机采样的种子页面 \(v_{seed} \sim \mathcal{V}\) 出发,沿出边遍历收集 \(k\) 个连接节点,形成一个局部依赖子图:
\[ \mathcal{G}_{sub} = \{v_{seed}\} \cup \{v_i \mid (v_{seed}, v_i) \in \mathcal{E}\}_k \]这一步模拟了自然的「由一个线索导向另一个线索」的信息发现过程。
第二步:实体提取(Entity Extraction)
子图 \(\mathcal{G}_{sub}\) 的原始内容通常包含大量噪声,会分散生成模型的注意力。为此,识别种子页面 \(v_{seed}\) 的中心主题 \(y_{theme}\),然后提取子图中与该主题直接或间接相关的关键实体,重新组织为实体子图 \(\mathcal{G}_{entity}\)。在这一结构中,节点表示提取的实体,边保留原始拓扑连接。
这一步骤有效地将 \(\mathcal{G}_{sub}\) 抽象为稠密的关系结构,去除文本噪声同时保留必要的逻辑路径。
第三步:问题生成(Question Generation)
为避免生成可通过简单查表解决的问题,生成器 \(P_{gen}\) 在显式结构约束下生成初版问题 \(q_{init}\):从 \(q_{init}\) 推导 \(y_{theme}\) 必须遍历 \(\mathcal{G}_{entity}\) 中的多条边。这强制 Agent 进行序列化的多节点演绎推理,而非单步检索。
第四步:实体模糊化与问题模糊化
合成问题旨在驱动 Agent 进行多步 ReAct 推理。然而,Agent 常常利用问题中的特定关键词走捷径,通过直接搜索绕过推理过程。为解决这一问题,OpenSeeker 引入了模糊化算子 \(\Phi\):
\[ \tilde{e} = \Phi(e) \]将具体实体 \(e\) 映射为模糊的描述性指代 \(\tilde{e}\),生成模糊实体子图 \(\tilde{\mathcal{G}}_{entity}\)。在最终的问题模糊化阶段,生成器融合模糊描述,将 \(q_{init}\) 重写为最终问题 \(\tilde{q}\),同时保持目标答案 \(y = y_{theme}\) 不变。
⇒ 最终产生的问题在结构上强制多步导航,且语义上的模糊性模拟了真实用户查询的不确定性。
第五步:双重标准拒收采样验证
为确保合成的问题-答案对 \((\tilde{q}, y)\) 既具有挑战性又逻辑有效,OpenSeeker 采用基于两个指示函数的拒收采样方案:
标准一——难度验证(严格工具必要性):\(\mathbb{I}[\pi_{base}(\tilde{q}) \neq y]\)。令强基础模型 \(\pi_{base}\) 在闭卷(无外部工具)设置下回答问题。若模型仅凭参数记忆就能正确回答,问题被丢弃。
标准二——可解性验证(逻辑一致性):\(\mathbb{I}[\pi_{base}(\tilde{q} \mid \mathcal{G}_{entity}) = y]\)。将实体子图 \(\mathcal{G}_{entity}\) 的完整内容作为上下文提供给模型(预言机设置)。若模型仍无法推导出 \(y\),说明推理路径已断裂或存在幻觉,该样本被拒绝。
QA 合成的三大核心优势:
(1) 事实锚定:将查询锚定在真实网络拓扑上而非依赖 LLM 生成,显著降低幻觉风险;
(2) 可扩展性:利用 ~68GB 英文和 ~9GB 中文网络数据,将开放网络转化为取之不尽的训练数据源;
(3) 可控性:通过调节子图大小 \(k\) 来校准推理复杂度和信息覆盖范围,可构建量身定制的课程学习路径。
去噪轨迹合成:解耦生成上下文与训练上下文
构建高质量搜索轨迹需要在信息保留和上下文窗口约束之间取得严格平衡。在网络规模的搜索中,原始观测往往被无关噪声所主导。OpenSeeker 提出了一个在生成上下文(教师)与训练上下文(学生)之间进行技术解耦的合成框架。

问题形式化
定义一个搜索轨迹为序列:
\[ \tau = [q, (r_1, a_1, o_1), \dots, (r_T, a_T, o_T), y] \]其中 \(q\) 为问题,\(r_t\) 为推理步骤(思维链),\(a_t\) 为动作(工具调用),\(o_t\) 为观测(工具响应),\(y\) 为最终答案。目标是合成能最优导向 \(y\) 的推理路径 \(r_t\) 和动作 \(a_t\)。
动态上下文去噪:回顾式摘要机制
在轨迹合成过程中,采用回顾式摘要机制。在第 \(t\) 轮,Agent 基于当前上下文 \(\mathcal{H}_t\) 生成推理-动作对 \((r_t, a_t)\)。上下文构建遵循「摘要化长期历史 + 原始近期上下文」协议:
\[ \mathcal{H}_t = \{q, \underbrace{(r_1, a_1, s_1), \dots, (r_{t-2}, a_{t-2}, s_{t-2})}_{\text{摘要化长期历史}}, \underbrace{(r_{t-1}, a_{t-1}, o_{t-1})}_{\text{原始短期上下文}}\} \]其中 \(s_i = \text{Summarize}(o_i \mid \text{context})\) 表示观测 \(o_i\) 的压缩语义摘要。该机制在两个阶段间循环运作:
① 决策阶段(信息使用):为生成当前决策 \((r_t, a_t)\),Agent 获得 \(\mathcal{H}_t\),其中包含紧邻上一轮的完整原始观测 \(o_{t-1}\)。这确保 Agent 能够访问最近观测中的所有潜在信号来指导下一步移动。
② 压缩阶段(上下文去噪):一旦第 \(t\) 轮结束并获得新观测 \(o_t\),系统回顾式地调用摘要器将先前观测 \(o_{t-1}\) 压缩为 \(s_{t-1}\)。该摘要随后替换长期历史中的 \(o_{t-1}\)。这种滚动窗口方法有效过滤噪声,实现超长轨迹生成而不出现性能退化。
非对称上下文训练:内化去噪能力
为培养最终 Agent 的鲁棒性,OpenSeeker 在合成数据格式和训练数据格式之间定义了战略性的不对称:
合成数据(教师):轨迹使用包含摘要的干净、去噪上下文 \(\mathcal{H}_t\) 生成。这充当"脚手架",使教师模型能够在不受过多噪声干扰的情况下产生"黄金"推理路径。
训练数据(学生):对于最终训练数据集,剥离摘要、恢复完整原始上下文:
\[ \mathcal{H}^{train}_t = \{q, (r_1, a_1, o_1), \dots, (r_{t-1}, a_{t-1}, o_{t-1})\} \]学生模型被监督以在给定噪声原始上下文 \(\mathcal{H}^{train}_t\) 的条件下,预测教师模型产出的最优 \(r_t, a_t\)。这迫使学生隐式地学习去噪和信息提取能力,有效地将上下文去噪逻辑内化到自身参数中,以应对真实世界的非结构化数据。
非对称训练的核心思想:教师用「干净」的上下文产生高质量决策,学生被强制在「噪声」上下文中复现这些决策——类似于「戴着镣铐跳舞」,迫使学生学会自主从噪声中提取关键信号。
实验
实验设置
模型初始化:OpenSeeker 基于 Qwen3-30B-A3B-Thinking-2507 初始化,总参数 30B,推理时激活 3B。最大工具调用次数 200,上下文窗口 256K。
训练细节:仅进行单次 SFT 训练(受限于计算资源,无超参调优、无启发式数据过滤),每个训练样本包含用户问题 \(q\) 以及完整的原始推理步骤、工具调用和工具响应的序列。
评估基准:
- BrowseComp(英文)/ BrowseComp-ZH(中文):测试多步导航和困难信息定位
- xbench-DeepSearch:评估复杂深度研究能力,如规划与综合
- WideSearch:衡量广泛信息检索中的可靠性
主要实验结果
下表展示了 OpenSeeker 与各基线模型在四个基准上的完整对比。
| 模型 | 样本数 | 开源样本 | 训练方式 | 学术团队 | BrowseComp | BC-ZH | xbench | WideSearch |
|---|---|---|---|---|---|---|---|---|
| 闭源专有模型 | ||||||||
| Claude-4.5-Sonnet | ? | 0 | ? | ✗ | 24.1 | 42.4 | - | - |
| OpenAI-o3 | ? | 0 | ? | ✗ | 49.1 | 68.7 | - | 60.0 |
| GPT-5-High | ? | 0 | ? | ✗ | 54.9 | 63.0 | - | - |
| 开源模型 > 30B | ||||||||
| DeepSeek-V3.2-671B | ? | 0 | ? | ✗ | 51.4 | 65.0 | - | - |
| GLM-4.7-357B | ? | 0 | ? | ✗ | 52.0 | 66.6 | - | - |
| ~30B 级别模型 | ||||||||
| MiroThinker-32B (SFT+RL) | 147K | 147K | SFT+RL | ✗ | 13.0 | 17.0 | - | - |
| DeepDive-32B | 4.1K | 4.1K | SFT+RL | ✗ | 15.3 | 29.7 | 51.8 | - |
| WebSailor-V2-30B (SFT+RL) | ? | 0 | SFT+RL | ✗ | 35.3 | 44.1 | 73.7 | - |
| WebLeaper-30B | 15K | 0 | SFT | ✗ | 27.7 | - | 66.0 | 44.1 |
| Tongyi DeepResearch | ? | 0 | CPT+SFT+RL | ✗ | 43.4 | 46.7 | 75.0 | - |
| OpenSeeker-v1-30B-SFT | 11.7K | 11.7K | SFT | ✓ | 29.5 | 48.4 | 74.0 | 59.4 |
表1:OpenSeeker 与各类搜索 Agent 的全面对比。"样本数"为训练数据总量,"开源样本"为开源数据量,"训练"表示训练技术(CPT:持续预训练,SFT:监督微调,RL:强化学习),"学术团队"表示是否由纯学术团队完成。OpenSeeker 在 BrowseComp-ZH 上超越通过 CPT+SFT+RL 训练的通义 DeepResearch,且在 所有仅使用 SFT 的 Agent 中表现最优
从实验结果中可以提炼出以下关键发现:
① 超越资源密集的工业界基线:OpenSeeker 仅使用 11.7K 样本和标准 SFT 协议,在 BrowseComp-ZH 上取得 48.4 分,超越阿里巴巴通义 DeepResearch(46.7)。后者采用了持续预训练(CPT)+ SFT + 强化学习(RL)的复杂、资源密集型训练流程——OpenSeeker 仅靠高质量 SFT 数据就实现了超越。
② 同训练设置下性能碾压:在 ~30B 参数级别、同使用 SFT 训练的模型中,OpenSeeker 展现出压倒性优势。在 BrowseComp-ZH 上以 48.4 的成绩领先第二名 WebSailor-V2-SFT(28.3)近 20 个百分点。值得注意的是,数据量并非决定性因素——MiroThinker 的 147K 样本远多于 OpenSeeker 的 11.7K,但性能却显著落后,印证了数据质量 > 数据量。
③ 同等数据量下的效率优势:与使用 10K-15K 样本的 WebSailor-V2 和 WebLeaper 配置相比,OpenSeeker 在所有基准上表现更优。在 xbench 和 WideSearch 上,分别超出最佳基线组合近 8%(74.0 vs 66.0)和 15%(59.4 vs 44.1)。
SFT 模型横向对比
| 数据 | 样本数 | 开源样本 | 学术团队 | BrowseComp | BC-ZH | xbench | WideSearch |
|---|---|---|---|---|---|---|---|
| DeepDive-32B | 4.1K | 4.1K | ✗ | 9.5 | 23.0 | 48.5 | - |
| MiroThinker-32B-v0.1 | 147K | 147K | ✗ | 10.6 | 13.8 | - | - |
| WebSailor-V2-30B (SFT) | ? | 0 | ✗ | 24.4 | 28.3 | 61.7 | - |
| WebLeaper-30B | 15K | 0 | ✗ | 27.7 | - | 66.0 | 44.1 |
| OpenSeeker-v1-30B-SFT | 11.7K | 11.7K | ✓ | 29.5 | 48.4 | 74.0 | 59.4 |
表2:SFT 训练的模型性能对比。OpenSeeker 在所有四个基准上一致且显著表现最优,仅用 11.7K 训练样本
数据难度分析
为量化合成数据与标准基准的难度对比,作者使用同一开源模型对合成样本和 BrowseComp 基准进行推理。结果表明,OpenSeeker 的合成数据在难度上匹配甚至超越已建立的基准。
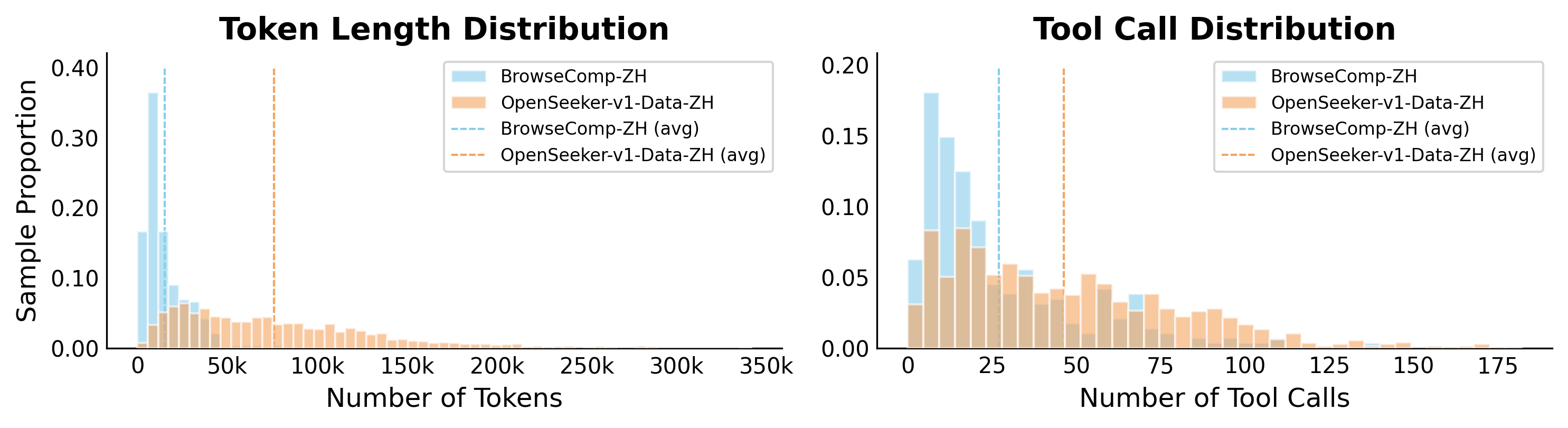
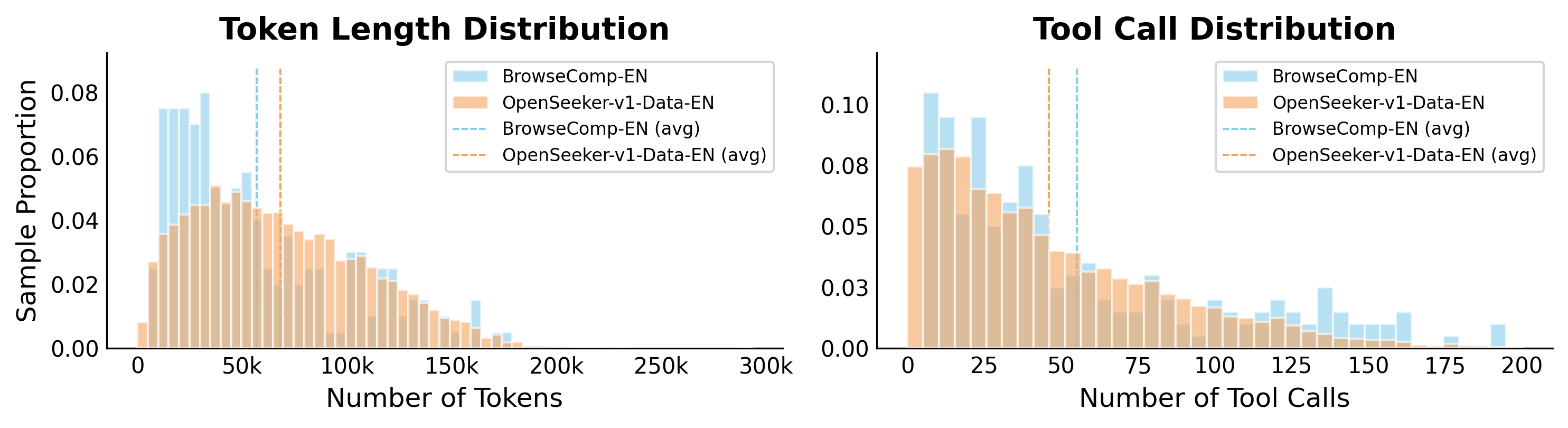
与同期工作的对比
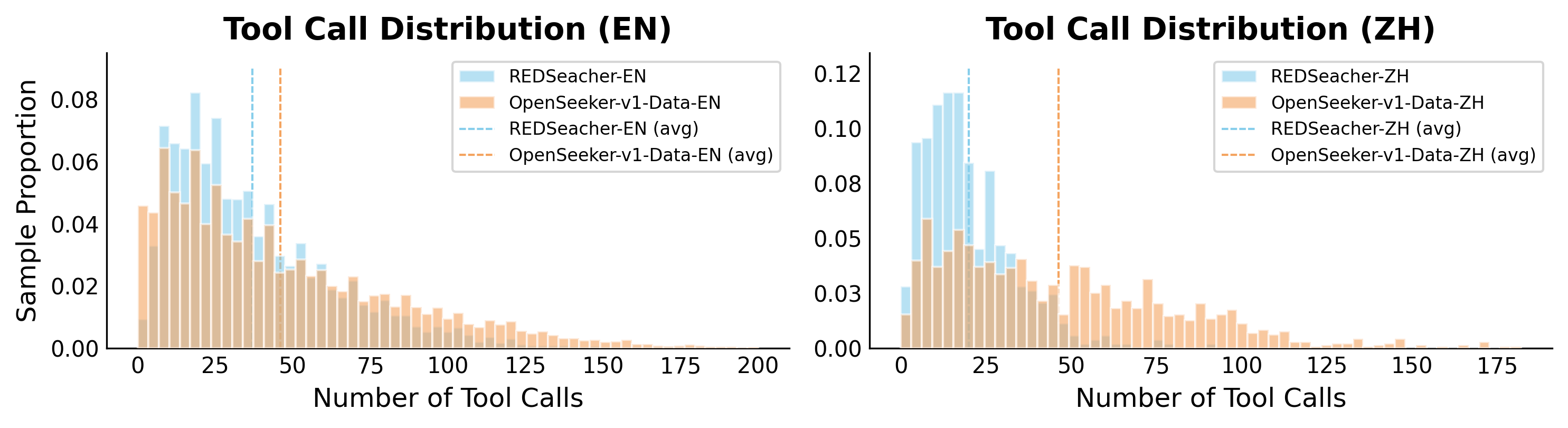
与同期工作相比,OpenSeeker 展现出显著优势。在 SFT 训练设置下,OpenSeeker 在 BrowseComp-ZH 上比 REDSearcher 高出 21.6%(48.4% vs 26.8%),且仅使用 11.7K 样本就超越了使用 96K 样本的 OpenResearcher。数据难度分析进一步验证了这一点:OpenSeeker 的合成轨迹在平均工具调用次数上显著高于 REDSearcher。
讨论
打破企业数据垄断
长期以来,高性能搜索 Agent 的发展一直是科技巨头主导的「闭门游戏」,高质量数据是它们的主要护城河。与此同时,现有的开源数据集往往质量不佳、推理复杂度不足,使学术界难以训练真正具备前沿能力的搜索模型。
OpenSeeker 针对这一关键瓶颈给出了明确的答案:通过完全开源高保真训练数据,为社区提供了复现和构建工业级能力所需的完整资源,打破了长期存在的「数据护城河」。这是首个由纯学术团队在前沿搜索基准上达到最先进水平并同时完全开源训练数据的工作。
关键洞察:数据质量 > 数据量 > 训练规模。OpenSeeker 用 11.7K 高质量合成数据 + 简单 SFT + 单次训练,超越了使用 147K 数据、CPT+SFT+RL 多阶段训练的工业界方案。这一结果表明,战略性数据合成是弥合学术界与工业界搜索 Agent 性能差距的有效路径。
未来工作
当前工作仅代表了 OpenSeeker 潜力的下界。由于计算资源限制,仅进行了单次训练,限制了在更具挑战性数据上的效果验证以及各种参数和数据过滤策略的探索。后续工作计划:
- 优化数据分布,实施严格的质量过滤
- 生成更高复杂度的训练数据以推动性能边界
- 将 Agent 能力扩展到纯网络搜索之外,整合更多样化的工具和数据源
- 探索多阶段的 RL 训练以进一步释放模型潜力
总结
OpenSeeker 的核心贡献可以归纳为:
① 识别核心瓶颈:明确指出高质量训练数据的垄断是阻碍开源搜索 Agent 社区发展的根本瓶颈。企业通过数据不公开维持"数据护城河",学术界长期缺乏可用的高质量训练资源。
② 两项技术创新:提出了 基于事实的可扩展可控 QA 合成——从真实网络图谱逆向构建强制多跳推理的复杂问题;以及 去噪轨迹合成——通过回顾式摘要机制与不对称训练,使学生模型学会从噪声中提取关键信号。
③ 完全开源:作为首个由纯学术团队实现前沿级搜索性能并完全开源训练数据、合成方案和模型权重的工作,OpenSeeker 为社区提供了完整的可复现方案。
④ 高效性验证:仅用 11.7K 合成样本、简单 SFT 和单次训练,即在四个基准上达到或超越工业界通过大规模多阶段训练取得的性能,充分验证了数据质量优先的范式有效性。
核心启示:在搜索 Agent 领域,战略性数据合成是实现高质量训练的有效途径。通过精心设计的数据合成 pipeline,学术团队完全可以打破企业的数据垄断,训练出具有竞争力的前沿级搜索 Agent。这为开源社区指明了方向——与其等待企业公开训练数据,不如自己创造出比企业数据更高质量的合成训练数据。
Reference
[1] OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data — Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, Siheng Chen. arXiv:2603.15594, 2026.
[2] OpenSeeker GitHub Repository
[3] OpenSeeker Training Dataset on Hugging Face
[4] OpenSeeker Model Weights on Hugging Face
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!