Relearning PPO
在重要性采样中,$\pi_\theta$ 和 $\pi_{old}$ 差距不能太大。
TRPO
PPO 之前的一种强化学习算法,通过利用 $\pi_\theta$ 和 $\pi_{old}$ 之间的 KL 散度作为约束来指导优化:
$$ \begin{aligned} \underset{\theta}{\max}&\quad\hat{\mathbb E}_t\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat A_t\right]\\ {\rm subject\text{ }to}&\quad\hat{\mathbb{E}}_t[{\rm KL}[\pi_{\theta_{old}}(\cdot|s_t),\pi_\theta(\cdot|s_t)]]\le\delta \end{aligned} $$自然的改进思路是用惩罚项代替优化目标中的约束,即:
$$ \underset{\theta}{\max}\hat{\mathbb E}_t\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{old}(a_t|s_t)}\hat{A}_t-\beta{\rm KL}[\pi_{old}(\cdot|s_t),\pi_\theta(\cdot|s_t)]\right] $$PPO-Penalty
使用一个固定的超参数 $\beta$ 难以适应学习过程中的复杂变化 ⇒ 自适应 KL 惩罚系数 (Adaptive KL Penalty Coefficient)。根据训练过程中的 KL 散度,对 $\beta$ 进行动态调节。
- 使用多个 epochs 的 minibatch SGD 来优化 KL 散度惩罚系数: $$ L^{KLPEN}(\theta)=\hat{\mathbb E}_t\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat{A}_t-\beta{\rm KL}[\pi_{\theta_{old}}(\cdot|s_t),\pi_\theta(\cdot|s_t)]\right] $$
- 计算 $d= \hat{\mathbb E}_t[{\rm KL}[\pi_{\theta_{old}}(\cdot|s_t),\pi_\theta(\cdot|s_t)]]$:
- $d\lt d_{targ}/1.5,\quad\beta\leftarrow\beta/2$
- $d>d_{targ}\times 1.5,\quad\beta\leftarrow\beta\times 2$
相较于固定 $\beta$ 在实验中存在效果提升,但效果没有裁剪的方法好,PPO-Clip 也是目前使用的方法。
PPO-Clip
令 $r_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$,即概率的比值,TRPO 最大化的目标是:
$$ L^{CPI}(\theta)=\hat{E}_t\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat{A}_t\right]=\hat{E}_t[r_t(\theta)\hat{A}_t] $$其中 CPI 指保守策略迭代(Conservative Policy Iteration)。
PPO 将裁剪加入约束,防止 $r_t$ 偏离 1,优化目标为:
$$ L^{CLIP}(\theta)=\hat{E}_t[\min(r_t(\theta)\cdot\hat{A}_t,\text{clip}(r_t(\theta),1-\epsilon, 1+\epsilon)\cdot\hat A_t)] $$裁剪实际为优化目标划定了上界:
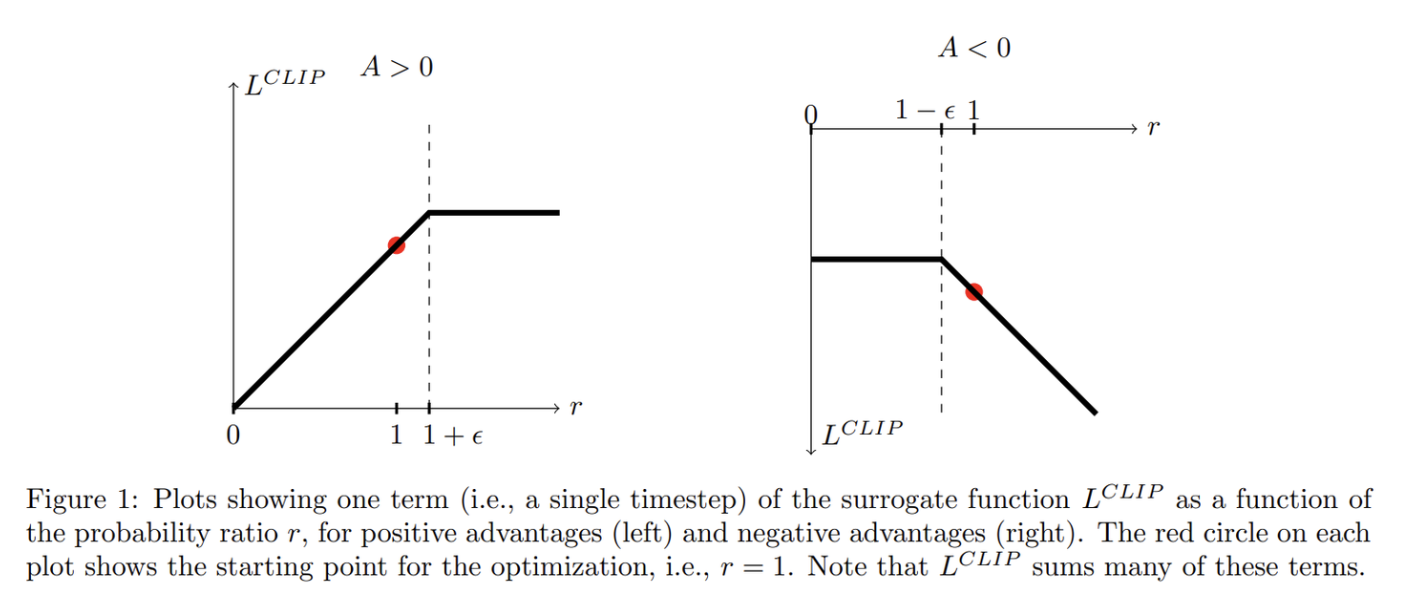
- $\hat A_t>0$:优势为正,则 $a_t$ 好于平均水平,可提升 $\pi_\theta(a_t|s_t)$,但可能存在采样不足导致估计错误的情况,因此 $\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$ 存在上限。当 $r_t(\theta)>1+\epsilon$ 进行裁剪,使得 $L^{CLIP}(\theta)\le (1+\epsilon)\hat A_t$。
- $\hat A_t<0$:优势为负,则 $a_t$ 差于平均水平,可降低 $\pi_\theta(a_t|s_t)$,同样可能存在采样不足导致估计错误的情况,因此 $\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$ 存在下限。当 $r_t(\theta)<1-\epsilon$ 进行裁剪,使得 $L^{CLIP}(\theta)\le (1-\epsilon)\hat A_t$。
Critic Optimization
$$ \arg\min_{V_\pi}L(V_\pi)=E_t[(r_t+\gamma V_\pi(s_{t+1})-V_\pi(s_t))^2] $$Critic Network 会不断拟合新策略的价值函数,由于 Critic 更新有限,价值网络的更新也应被限定在一个范围内。
改进一:利用 $A_{\pi}^{GAE}(s_t,a_t)+V_\pi^{old}(s_t)$ 取代 $r_t+\gamma V_\pi(s_{t+1})$ 作为真实收益
利用优势刻画实时收益信息,将 $A_{\pi}^{GAE}(s_t,a_t)$ 简写为 $A_t^{GAE}$:
$$ \begin{aligned} A_t^{GAE}+V_\pi^{old}(s_t)&=\delta_t+\gamma\lambda A_{t+1}^{GAE}+V_\pi^{old}(s_t)\\ &=(r_t+\gamma V_\pi^{old}(s_{t+1})-V_\pi^{old}(s_t))+\gamma\lambda A_{t+1}^{GAE}+V_\pi^{old}(s_t)\\ &=r_t+\gamma V_\pi^{old}(s_{t+1})+\gamma\lambda A_{t+1}^{GAE} \end{aligned} $$视作用 GAE 通过 $\lambda$ 参数平衡偏差与方差。记 $R_t=A_t^{GAE}+V_\pi^{old}(s_t)$。
改进二:用更新前的 $V_\pi^{old}$ 限制 $V_\pi$ 范围
Actor 优化目标会用 CLIP 作限制,对 Critic 的输出也需要做裁剪:
$$ V_\pi^{CLIP}(s_t)=\text{clip}(V_\pi(s_t), V_\pi^{old}(s_t)-\epsilon,V_\pi^{old}(s_t)+\epsilon) $$ $$ \arg\min_{V_\pi}L(V_\phi)=E_t\left[\max\left[(V_\pi(s_t)-R_t)^2,(V_\pi^{CLIP}(s_t)-R_t)^2\right]\right] $$优化目标是最小化 $L(V_\pi)$,为什么要取 $\max$?
- 若 $V_\pi(s_t)$ 落在 $V_\pi^{old}(s_t)$ 的 $\pm \epsilon$ 区间内,则 $V_\pi^{CLIP}(s_t)=V_{\pi}(s_t)$,梯度正常更新: $$ \frac{\partial L}{\partial V_{\pi}(s_t)}=2(V_\pi(s_t)-R_t) $$
- 若 $V_\pi(s_t)$ 偏离 $V_\pi^{old}(s_t)$ 的 $\pm \epsilon$ 区间,且 $(V_\pi(s_t)-R_t)^2$ 更大,梯度同上。
- 若 $V_\pi(s_t)$ 偏离 $V_\pi^{old}(s_t)$ 的 $\pm \epsilon$ 区间,且 $(V_\pi^{CLIP}(s_t)-R_t)^2$ 更大,此时:发生 CLIP 则说明 Critic 已经更新得离原始参数较远,$(V_\pi^{CLIP}(s_t)-R_t)^2$ 更大说明此时 $V_\pi(s_t)$ 已经较 $V_\pi^{CLIP}(s_t)$ 而言更接近 $R_t$,Critic 已经学对了。因此应该停止更新: $$ \frac{\partial L}{\partial V_{\pi}(s_t)}=2(V_\pi^{CLIP}(s_t)-R_t)\cdot\frac{\partial V_\pi^{CLIP}(s_t)}{\partial V_\pi(s_t)}=0 $$
因此,该优化目标可以使价值函数向正确方向完成小步更新,从而保证训练稳定性。
PPO Optimization Objective
Actor
$$ \arg\max_{\pi_\theta}J(\pi_\theta)=E_t[\min\{r_t(\theta)A_t^{GAE},~\text{clip}(r_t(\theta),1-\epsilon,1+\epsilon)\cdot A_t^{GAE}\}] $$Critic
$$ V_\pi^{CLIP}(s_t)=\text{clip}(V_\pi(s_t), V_\pi^{old}(s_t)-\epsilon,V_\pi^{old}(s_t)+\epsilon) $$ $$ \arg\min_{V_\pi}L(V_\pi)=E_t[\max\{(A_t^{GAE}+V_\pi^{old}(s_t)-V_\pi(s_t))^2,~(A_t^{GAE}+V_\pi^{old}(s_t)-V_\pi^{CLIP}(s_t))^2\}] $$PPO 与 LLM 结合
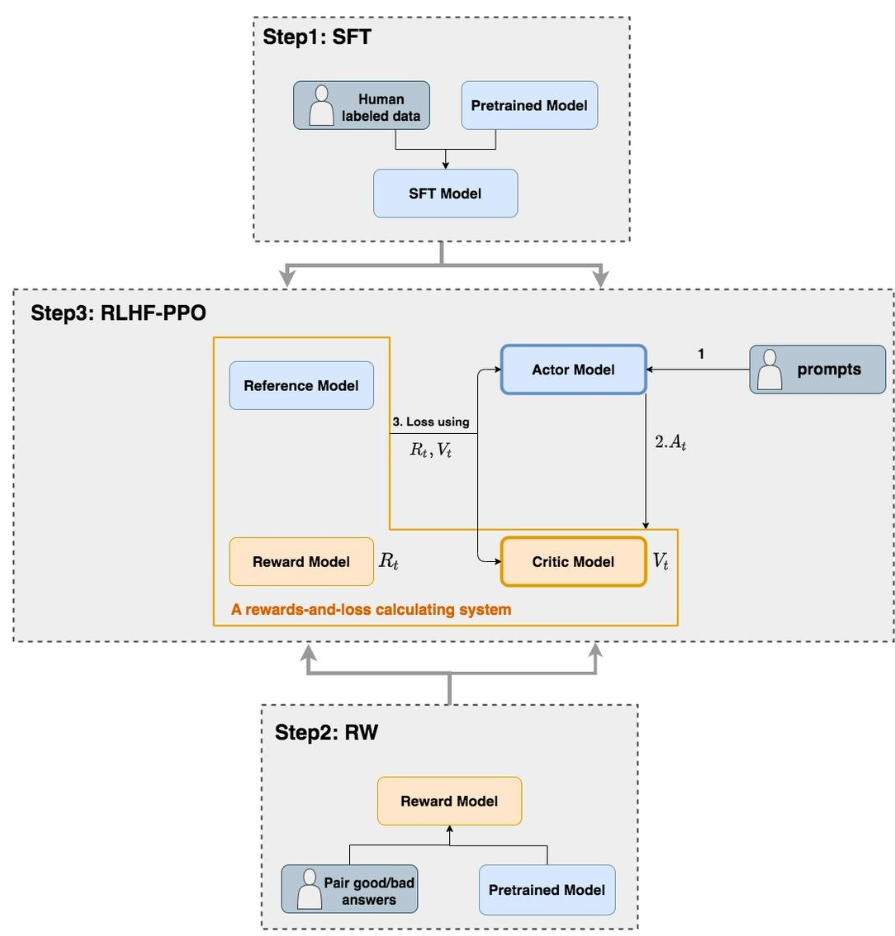
- Agent → LLM
- 状态:prompt + 模型输出 response
- 动作:生成下一个 token。Action Space:词表。输出下一个 token 的概率分布 logits ⇒ 随机性策略
- 状态转移:确定性。LLM 输出某个 token,状态则变为上文 + 新 token
- 奖励:生成 token / 文本的质量
- 优势:由参考模型 Reference Model 和奖励模型 Reward Model 计算得到,在 RLHF 过程中,这两个模型无需训练和更新。作用:提供 Actor 和 Critic 优化目标中的优势
RM Training
偏好数据集形式:每个样本包含一个 chosen 回复和 rejected 回复。RM 的网络结构是语言模型,最后增加了一个 value head 输出每个位置的分数。一个句子的分数 = Last Token 的分数。
⇒ 训练目标:尽量增大 chosen 回复和 rejected 回复分数的差值。
{
"conversations": [
{
"from": "human",
"value": "详细说明:在这个任务中,我们要求您回答一个关于某个事件之前或之后可能发生的事件的问题。例如,“赚钱”通常会出现在“花钱”之前。请注意,许多问题可能有多个正确答案。我们只需要一个最有可能的答案。请尽量保持您的“答案”尽可能简单。简洁明了的“答案”优于复杂冗长的回答。\n问题:句子:自然堤防 洪水泛滥的河流通常会在河岸形成自然堤防。\n问题:一旦形成堤防会发生什么?\n解决方案:"
}
],
"chosen": {
"from": "gpt",
"value": "答案:堤坝阻止了河水水位上涨,减少了洪水。"
},
"rejected": {
"from": "gpt",
"value": "一旦堤坝形成,它可以通过提高河岸和引导水流远离相邻的土地区域来防止未来的洪水。"
}
}
损失函数 Pairwise Ranking:
$$ L=-\log\sigma(r_{chosen}-r_{rejected}) $$def compute_loss(
self,
model: "PreTrainedModel",
inputs: Dict[str, "torch.Tensor"],
return_outputs: bool = False
) -> Union["torch.Tensor", Tuple["torch.Tensor", List["torch.Tensor"]]]:
"""
计算成对偏好损失。前n个样本为选中的样本,后n个样本为被拒绝的样本。
"""
# 前向传播,获取价值预测
# values shape: [2 * batch_size, seq_len, 1]
_, _, values = model(**inputs,
output_hidden_states=True,
return_dict=True,
use_cache=False)
# 计算单侧批次大小(总批次大小的一半)
batch_size = inputs["input_ids"].size(0) // 2
# 将注意力掩码分成选中和拒绝两部分
chosen_masks, rejected_masks = torch.split(inputs["attention_mask"], batch_size, dim=0)
# 将价值预测分成选中和拒绝两部分
chosen_rewards, rejected_rewards = torch.split(values, batch_size, dim=0)
# 获取每个序列最后一个非填充位置的价值
chosen_scores = chosen_rewards.gather(
dim=-1,
index=(chosen_masks.sum(dim=-1, keepdim=True) - 1)
)
rejected_scores = rejected_rewards.gather(
dim=-1,
index=(rejected_masks.sum(dim=-1, keepdim=True) - 1)
)
# 移除多余的维度
chosen_scores, rejected_scores = chosen_scores.squeeze(), rejected_scores.squeeze()
# 计算偏好损失:-log(sigmoid(chosen_score - rejected_score))
loss = -torch.nn.functional.logsigmoid(
chosen_scores.float() - rejected_scores.float()
).mean()
if return_outputs:
return loss, (loss, chosen_scores, rejected_scores)
else:
return loss
Reference Model
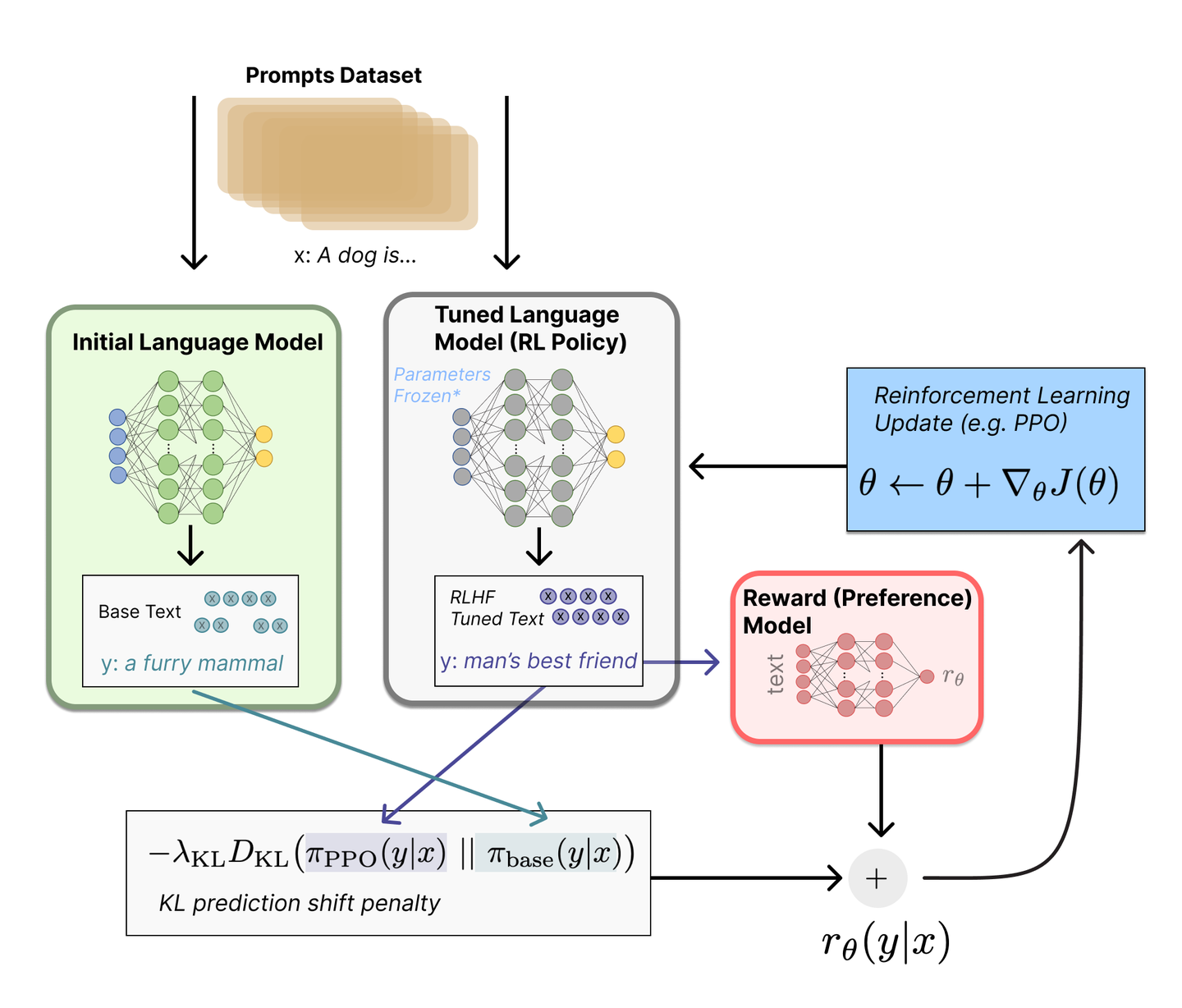
RM 是对一个完整的 Response 打分,如何获取每一个动作(每一个 token 输出)的即时奖励?⇒ 利用 Reference Model。
Reference Model $\pi_{ref}$ 和 Actor 的初始权重 $\pi_\theta$ 一致,来自 LLM 预训练后,之后的 Training 过程中,Reference Model 不再训练。
作用:在 RLHF 阶段给 LLM 增加一些约束,防止 LLM 偏离原始模型太远,为满足偏好而丧失太多基础能力。基于 KL 散度来衡量距离:
$$ KL[\pi_\theta\|\pi_{ref}]=E_{\tau\sim\pi_\theta}\left[\log\frac{\pi_\theta(a_t|s_t)}{\pi_{ref}(a_t|s_t)}\right]=\text{log probs}-\text{ref log probs} $$计算轨迹的即时奖励:
$$ \begin{cases} R_t=-\text{KL\_CTL}\times \left(\log\frac{\pi_\theta(a_t|s_t)}{\pi_{ref}(a_t|s_t)}\right),&t\not= T\\ R_t=-\text{KL\_CTL}\times \left(\log\frac{\pi_\theta(a_t|s_t)}{\pi_{ref}(a_t|s_t)}\right) + R_t,&t=T \end{cases} $$- 在最后一个 token 前,奖励源于 Actor 和 Reference Model 保持较近的距离。
- 在最后一个 token 时,引入了整个句子的 RM 奖励。
def compute_rewards(
self,
scores: torch.FloatTensor,
logprobs: torch.FloatTensor,
ref_logprobs: torch.FloatTensor,
masks: torch.LongTensor,
):
"""
Compute per token rewards from scores and KL-penalty.
Args:
scores (`torch.FloatTensor`):
Scores from the reward model, shape (`batch_size`)
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
ref_logprobs (`torch.FloatTensor`):
Log probabilities of the reference model, shape (`batch_size`, `response_length`)
Returns:
Per token rewards, non_score_rewards, kls
"""
rewards, non_score_rewards, kls = [], [], []
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
# compute KL penalty (from difference in logprobs)
kl = self._kl_penalty(logprob, ref_logprob)
kls.append(kl)
non_score_reward = -self.kl_ctl.value * kl
non_score_rewards.append(non_score_reward)
reward = non_score_reward.clone()
last_non_masked_index = mask.nonzero()[-1]
# reward is preference model score + KL penalty
reward[last_non_masked_index] += score
rewards.append(reward)
return torch.stack(rewards), torch.stack(non_score_rewards), torch.stack(kls)
Reward Model 和 Reference Model 的作用是计算 $R_t$,策略迭代阶段无需。
Advantage Computation
PPO 优化目标中使用的是 Advantage 而非每一步的即时奖励 $R_t$:
$$ A_t^{GAE}=\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l} $$ $$ \delta_t = r_t+\gamma V_\pi(s_{t+1})-V_\pi(s_t) $$只需定义最后一个时刻 $V_\pi(s_T)=0$(已经结束,后续不可能获得奖励,状态价值为 0),可倒推每个时刻的 $\delta_t$ 和 GAE。
def compute_advantages(
self,
values: torch.FloatTensor, # 价值网络预测的状态值 [batch_size, seq_len]
rewards: torch.FloatTensor, # 每个时间步的奖励值 [batch_size, seq_len]
mask: torch.FloatTensor, # 用于处理填充的掩码 [batch_size, seq_len]
):
"""
计算广义优势估计(GAE)
"""
# 初始化最后一个GAE值为0
lastgaelam = 0
advantages_reversed = []
gen_len = rewards.shape[-1]
# 应用掩码到价值和奖励
values = values * mask # 将填充位置的价值置为0
rewards = rewards * mask # 将填充位置的奖励置为0
# 如果配置了奖励白化,对奖励进行标准化处理
if self.config.whiten_rewards:
rewards = masked_whiten(rewards, mask, shift_mean=False)
# 反向遍历序列计算GAE
for t in reversed(range(gen_len)):
# 获取下一个状态的价值(如果是最后一个状态则为0)
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
# 计算TD误差:reward + gamma * next_value - current_value
delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t]
# 计算GAE:当前TD误差 + gamma * lambda * 上一步的GAE
lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam
advantages_reversed.append(lastgaelam)
# 将反向计算的优势值转换为正向序列
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
# 计算总回报:优势 + 价值估计
returns = advantages + values
# 对优势进行标准化处理
advantages = masked_whiten(advantages, mask)
# 分离优势的计算图,防止梯度传播
advantages = advantages.detach()
return values, advantages, returns
其中的 Return $= A_t + V_t^{old}$,计算了 Critic 优化目标里的真实收益。
PPO-Epoch
通过重要性采样,将数据运用 ppo-epoch 次数之后(一般为 4),再令 $\pi_\theta^{old}=\pi_\theta$。
每个 ppo-epoch 内,$\pi_\theta$ 与 $\pi_\theta^{old}$ 比较,而非冻结的 $\pi_{ref}$。其中 $\pi_\theta^{old}$ 是上一个 batch 的训练结果。
Note:$\pi_\theta^{old}$ 是重要性采样时使用(但下面的代码中也会算 PPO 的 Old Policy KL 散度来确保模型更新步调较小),而 Reference Model 是计算 KL 散度时使用。
def loss(
self,
old_logprobs: torch.FloatTensor, # 旧策略的对数概率 [batch_size, seq_len]
values: torch.FloatTensor, # 旧的价值估计 [batch_size, seq_len]
logits: torch.FloatTensor, # 新策略的logits [batch_size, seq_len, vocab_size]
vpreds: torch.FloatTensor, # 新的价值估计 [batch_size, seq_len]
logprobs: torch.FloatTensor, # 新策略的对数概率 [batch_size, seq_len]
mask: torch.LongTensor, # 序列掩码 [batch_size, seq_len]
advantages: torch.FloatTensor, # 优势值 [batch_size, seq_len]
returns: torch.FloatTensor, # 总回报 [batch_size, seq_len]
):
"""计算PPO的策略损失和价值损失"""
# 1. 计算价值损失 (Value Loss)
# 将新的价值预测裁剪在旧价值预测的一定范围内
vpredclipped = clip_by_value(
vpreds,
values - self.config.cliprange_value, # 下界
values + self.config.cliprange_value, # 上界
)
# 计算两种价值损失:未裁剪和裁剪后的MSE
vf_losses1 = (vpreds - returns) ** 2 # 未裁剪的价值损失
vf_losses2 = (vpredclipped - returns) ** 2 # 裁剪后的价值损失
# 取两种损失中的较大值,并计算掩码平均
vf_loss = 0.5 * masked_mean(torch.max(vf_losses1, vf_losses2), mask)
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), mask)
# 2. 计算策略损失 (Policy Loss)
# 计算新旧策略的概率比
ratio = torch.exp(logprobs - old_logprobs) # exp(log(p_new/p_old)) = p_new/p_old
# 计算两种策略损失
pg_losses = -advantages * ratio # 未裁剪的策略损失
pg_losses2 = -advantages * torch.clamp(
ratio,
1.0 - self.config.cliprange, # 下界
1.0 + self.config.cliprange # 上界
)
# 取两种损失中的较大值
pg_loss = masked_mean(torch.max(pg_losses, pg_losses2), mask)
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).float(), mask)
# 3. 合并总损失:策略损失 + 价值系数 * 价值损失
loss = pg_loss + self.config.vf_coef * vf_loss
# 4. 比率阈值检查
avg_ratio = masked_mean(ratio, mask).item()
if avg_ratio > self.config.ratio_threshold:
warnings.warn(
f"The average ratio of batch ({avg_ratio:.2f}) exceeds threshold {self.config.ratio_threshold:.2f}. Skipping batch."
)
pg_loss = pg_loss * 0.0
vf_loss = vf_loss * 0.0
loss = loss * 0.0
# 5. 计算额外统计信息
entropy = masked_mean(entropy_from_logits(logits), mask)
# KL散度近似
approxkl = 0.5 * masked_mean((logprobs - old_logprobs) ** 2, mask)
policykl = masked_mean(old_logprobs - logprobs, mask)
return_mean, return_var = masked_mean(returns, mask), masked_var(returns, mask)
value_mean, value_var = masked_mean(values, mask), masked_var(values, mask)
# 6. 收集统计信息
stats = dict(
loss=dict(
policy=pg_loss.detach(),
value=vf_loss.detach(),
total=loss.detach()
),
policy=dict(
entropy=entropy.detach(),
approxkl=approxkl.detach(),
policykl=policykl.detach(),
clipfrac=pg_clipfrac.detach(),
advantages=advantages.detach(),
advantages_mean=masked_mean(advantages, mask).detach(),
ratio=ratio.detach(),
),
returns=dict(mean=return_mean.detach(), var=return_var.detach()),
val=dict(
vpred=masked_mean(vpreds, mask).detach(),
error=masked_mean((vpreds - returns) ** 2, mask).detach(),
clipfrac=vf_clipfrac.detach(),
mean=value_mean.detach(),
var=value_var.detach()
),
)
return pg_loss, self.config.vf_coef * vf_loss, flatten_dict(stats)
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!