RL in LLM: An Introduction
Basic Definition of RL in LLM
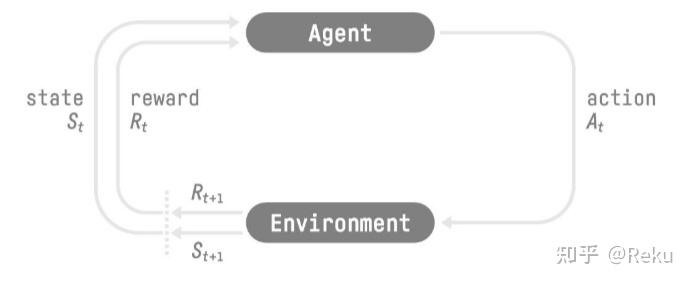
- 智能体(Agent):经过预训练和 SFT 的 LLM,可以对外界的输入做出回应,有一定的智能。
- 环境(Environment):其实是整个物理世界。如果是写算法题的话那就是 leetcode 平台,如果是 RLHF 的话,就是人类本身。
- 状态(State):环境的状态,这个东西在 LLM RL 里面有点模糊,不像游戏 AI 那么清晰;可以认为 LLM 之前的所有输出作为环境的状态吗?
- 动作(Action):对于 LLM 来说,就是 decode 过程中输出的每一个 token。
- 奖励(Reward):就是环境的反馈,比如人类喜不喜欢这个回答或者生成的代码能不能通过 leetcode 的评测,这里是搞头比较大的地方。
强化学习的三种做法
Actor $\pi$ (agent):基于环境状态和奖励做出决策;Critic $V_\pi$:基于当前环境状态和 actor 水平,判断状态价值。
- Value-based: Q-Learning — 只有 critic 的实体。如果 critic 能学得很好的话,actor 只需要看每一个决策 critic 的反应是什么,选 critic 反应最好的决策就行(假设 action 是离散的)。
- Policy-based: Policy Gradient — 只有 actor 的实体。人教人教不会,事教人一下就会。有时候不需要 critic,actor 只需要和环境做互动,从环境拿反馈就行。
- Actor-Critic — 两个实体都有,两个模型可以互相迭代。critic 的学习可能是有偏的,连续的 action 不好处理(value-based),而直接从环境拿反馈可能方差太大,训练不稳定(policy-based)。
Actor: Policy-based Method
目标是训练一个 actor policy $\pi_\theta(a_t|s_t)$,输入状态 $s_t$,输出动作空间 $A$ 中的某个动作,$\theta$ 是 Policy 学习的参数。
定义一个 Policy $\pi: s \to a$ 的好坏:
$$ \theta^* = \arg\max_{\theta} J_{\pi_\theta} $$ $$ J_{\pi_\theta} = \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_{t=0}^{\infty} \gamma^t r_t\right] = \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] = \sum_\tau R(\tau) P(\tau|\pi_\theta) $$其中 policy 和状态转移都是随机的,优化目标:最大化累积折扣奖励的期望 $\Rightarrow$ 训练过程需采样多次轨迹,在足够多样本上评估策略好坏。
轨迹 $\tau$ 是使用 $\pi_\theta$ 采样出来的,即 $\tau \sim \pi_\theta$:
$$ a_t \sim \pi_\theta(\cdot|s_t), \quad s_{t+1} \sim P(\cdot|s_t, a_t), \quad r_t = R(s_t, a_t, s_{t+1}) $$对优化目标的梯度:
$$ \begin{aligned} \nabla J_{\pi_\theta} &= \sum_\tau R(\tau) \nabla P(\tau|\pi_\theta) \\ &= \sum_\tau R(\tau) P(\tau|\pi_\theta) \frac{\nabla P(\tau|\pi_\theta)}{P(\tau|\pi_\theta)} \\ &= \sum_{\tau} R(\tau) P(\tau|\pi_\theta) \nabla \log P(\tau|\pi_\theta) \\ &= \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau) \nabla \log P(\tau|\pi_\theta)] \end{aligned} $$其中策略 $\pi_\theta$ 和状态转移均随机,假设一条轨迹有 $T$ 个 timestep:
$$ P(\tau|\pi_\theta) = p(s_0) \prod_{t=0}^{T-1} P(s_{t+1}|s_t, a_t) \pi_\theta(a_t|s_t) $$上式只有 $\pi_\theta(a_t|s_t)$ 与 $\theta$ 有关:
$$ \begin{aligned} \nabla \log(P(\tau|\pi_\theta)) &= \nabla\left[\log p(s_0) + \sum_{t=0}^{T-1} \log P(s_{t+1}|s_t, a_t) + \sum_{t=0}^{T-1} \log\pi_\theta(a_t|s_t)\right] \\ &= \sum_{t=0}^{T-1} \nabla \log \pi_\theta(a_t|s_t) \end{aligned} $$因此,策略梯度表达式为:
$$ \nabla J_{\pi_\theta} = \mathbb{E}_{\tau \sim \pi_\theta}\left[R(\tau) \sum_{t=0}^{T-1} \nabla \log \pi_\theta(a_t|s_t)\right] $$实践中,可以通过采样"足够多"的轨迹来估计期望。【大数定律】
假设采样 $N$ 条轨迹,$N \to \infty$,每条轨迹涵盖 $T_n$ 步,则梯度为:
$$ \nabla J_{\pi_\theta} \approx \frac{1}{N} \sum_{n=1}^N \sum_{t=0}^{T_n-1} R(\tau_n) \nabla \log \pi_\theta(a_t|s_t) $$对 $\nabla \log$ 的解释:由于 $\nabla \log \pi_\theta(a_t|s_t) = \frac{\nabla \pi_\theta(a_t|s_t)}{\pi_\theta(a_t|s_t)}$,等价于在每一个动作的梯度下,除以采样到这个动作的概率 $\Rightarrow$ 避免采样过程中采集到较多 低奖励高频率 的动作,否则会导致模型对其的偏好 $\Rightarrow$ 相当于利用 $\pi_\theta(a_t|s_t)$ 进行归一化。
同时,当前的奖励总是正值,会导致某些好的动作未被采样,但是采样到的坏动作的梯度永远为正 $\Rightarrow$ 模型训练失败 $\Rightarrow$ 轨迹的累积奖励 $R(\tau_n)$ 不应总为正值,可减去 baseline。
Critic: Value-based Method
回报:从某一时刻开始的所有未来奖励的累积。
假设轨迹长度为 $T$ 个 timestep,折扣回报:
$$ \begin{aligned} G_t &= \sum_{k=0}^{T-t-1} \gamma^k r_{t+k} \\ &= r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots + \gamma^{T-t-1} r_{T-1} \end{aligned} $$State-Value Function
$$ \begin{aligned} V_\pi(s_t) &= \mathbb{E}_\pi[G_t|s_t] \\ &= \mathbb{E}_\pi[r_t] + \mathbb{E}_\pi[\gamma G_{t+1}|s_t] \\ &= \mathbb{E}_\pi[r_t] + \mathbb{E}_\pi[\gamma V_\pi(s_{t+1})|s_t] \\ &= \sum_{a_t \in \mathcal{A}} \pi(a_t|s_t) \sum_{s_{t+1} \in \mathcal{S}} P(s_{t+1}|s_t, a_t)[r_t + \gamma V_\pi(s_{t+1})] \\ &= \mathbb{E}_{a_t \sim \pi(\cdot|s_t)}\left[\mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r_t + \gamma V_\pi(s_{t+1})]\right] \end{aligned} $$其中 $\mathbb{E}(V_\pi(s_{t+1})|s_t) = \mathbb{E}[G_{t+1}|s_t]$,即贝尔曼方程证明。
Action-Value Function
$$ \begin{aligned} Q_\pi(s_t, a_t) &= \mathbb{E}_\pi[G_t|s_t, a_t] \\ &= \mathbb{E}_\pi[r_t + \gamma(r_{t+1} + \gamma r_{t+2} + \cdots)|s_t, a_t] \\ &= \mathbb{E}_\pi[r_t + \gamma G_{t+1}|s_t, a_t] \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r_t + \gamma V_\pi(s_{t+1})] \end{aligned} $$$\Rightarrow$ 可以得到 State-Value Function 和 Action-Value Function 二者间关系:
$$ \begin{aligned} V_\pi(s_t) &= \mathbb{E}_{a_t \sim \pi(\cdot|s_t)}[Q_\pi(s_t, a_t)] \\ &= \sum_{a_t \in \mathcal{A}} \pi(a_t|s_t) Q_\pi(s_t, a_t) \end{aligned} $$Advantage and Temporal Difference (TD Error)
Advantage:在状态 $s_t$ 下,某个动作 $a_t$ 相对于平均水平有多好。即 $Q$ action-value 减去 $V$ state-value:
$$ \begin{aligned} A_\pi(s_t, a_t) &= Q_\pi(s_t, a_t) - V_\pi(s_t) \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t)] \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[\mathrm{TD\_error}] \end{aligned} $$其中 $\mathrm{TD\_error} = r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t)$。
$r_t$ 为即时奖励,$\gamma V_\pi(s_{t+1})$ 是下一状态 $s_{t+1}$ 的折扣价值,$V_\pi(s_t)$ 为当前状态价值。
$r_t + \gamma V_\pi(s_{t+1})$ 为实际观察到的价值估计。理论上 $V_\pi(s_t) = r_t + \gamma V_\pi(s_{t+1})$,但实际状态价值 $V_\pi$ 由一个需要训练的 Critic Model 给出,$r_t$ 由一个偏好数据上预先训练好的奖励模型给出(暂可认为是真实的即时奖励),因此 $\mathrm{TD\_error}$ 即为预测误差。
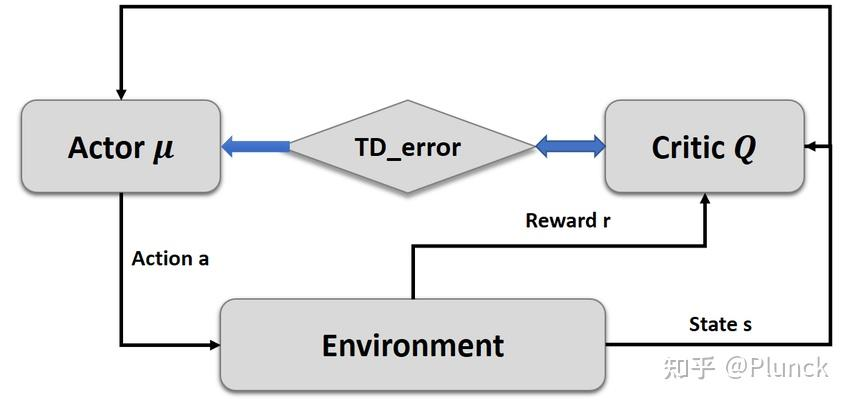
Actor-Critic
Data Pipeline
query → actor → (rollout) → answer → reward
Actor Optimization
和 SFT 的区别,对于 SFT 来说,所有样本同等重要,都要学习:
$$ \mathrm{SFT}_\nabla = \frac{1}{N} \sum_{i=1}^n \sum_{t=1}^{T_n-1} \nabla_\theta \log\pi_\theta(o_t|q, o_{\lt t}) $$其中 $n$ 是序列 seq 数量,$T_n$ 是 seq 长度 $\Rightarrow$ next token prediction loss。
而 RL 中会对不同的 action (decoding token) 给予不同的 Reward,相当于会对样本进行加权:
$$ \mathrm{Actor}_\nabla = \frac{1}{N} \sum_{i=1}^n \sum_{t=1}^{T_n-1} R(\tau_n) \nabla_\theta \log\pi_\theta(o_t|q, o_{\lt t}) $$其中 $R(\tau_n)$ 是每个 seq 的 Reward(不是每个 token):
$$ \mathrm{Actor}_\nabla = \frac{1}{N} \sum_{i=1}^n \sum_{t=1}^{T_n-1} R(\tau_n) \nabla_\theta \log\pi_\theta(a_t|s_t) $$其中 $a_t$ 为 action,$s_t$ 为状态,LLM RL 中的状态可以说就是之前输出的 token。
$R(\tau_n)$ 可以被定义为 $A_\pi(s_t, a_t)$,与 actor、current state、current action 都有关系 $\Rightarrow$ 优势函数:
$$ \mathrm{Actor}_\nabla = \frac{1}{N} \sum_{i=1}^n \sum_{t=1}^{T_n-1} A_\pi(s_t, a_t) \nabla_\theta \log\pi_\theta(a_t|s_t) $$优势函数 Advantage Function
$$ A_\pi(s_t, a_t) = r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t) $$其中 $r_t$ 是当前步骤的反馈,通过 reward model 计算;$V_\pi$ 是 critic model;$s_{t+1}$ 是 $s_t$ 通过 $a_t$ 的转移 $\Rightarrow$ 让 actor 满足 critic 需求,找到一个 $a_t$,使得 $s_{t+1}$ 尽可能好。
Critic Optimization
$$ V_\pi(s_t) = r_t + \gamma V_\pi(s_{t+1}) $$后续状态对前面影响会越来越小。Critic Loss 可以用(而且比较适合)MSE:
$$ \mathrm{Critic}_{loss} = (r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t))^2 $$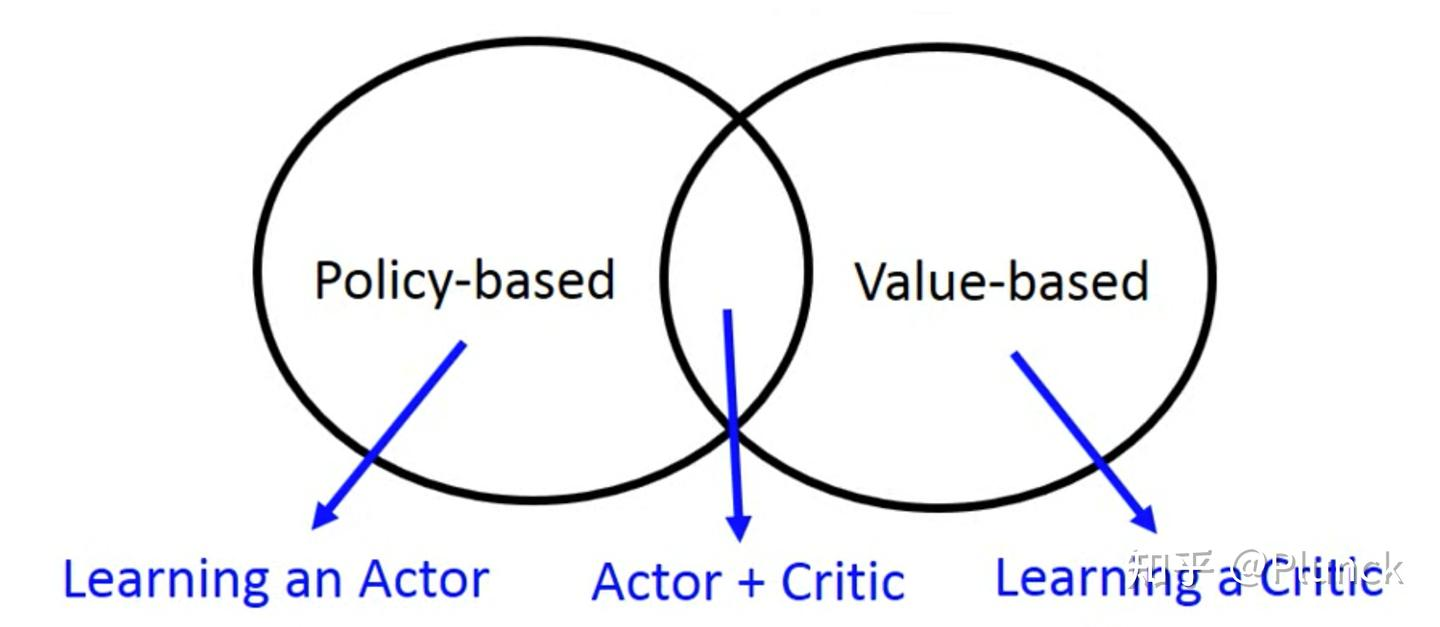
Actor-Critic Optimization
(1)策略改进阶段 Policy Improvement
给定 $\pi$ 和价值函数 $V_\pi$,通过优势函数 $A_\pi(s_t, a_t)$ 指导策略更新。
优势函数:量化在状态 $s_t$ 下选择动作 $a_t$ 相对于当前策略的预期表现。
策略更新方向:增加具有正优势值的动作的选择概率,使得策略收敛到新策略 $\pi'$。
收敛条件:策略 $\pi^*$ 的最优性:对于任意状态 $s$,最优动作 $a_s^*$ 的选择概率达到最大,优势函数 $A_{\pi^*}(s, a^*_s) \to 0$,此时 $\pi(a_{s}^*|s) \to 1$,策略可以可靠地选择最优动作。
(2)价值评估阶段 Policy Evaluation
策略从 $\pi$ 更新到 $\pi'$ 时,需要更新价值函数估计,即:
$$ V_{\pi'} = \mathbb{E}_{\pi'}[R(\tau)|s] $$其中 $R(\tau)$ 是在策略 $\pi'$ 下的轨迹回报。
Importance Sampling
Policy 根据其与数据生成方式的关系分为 on-policy 和 off-policy:
- On-Policy:直接从目标策略(当前学习和评估的策略)中采样数据,要求学习算法和行为策略一致 $\Rightarrow$ 生成数据的策略必须是当前优化的策略。
- Off-Policy:允许从与目标策略不同的行为策略中采样数据。
实践过程中,通常为了降低采样成本,提高训练效率,希望对得到的一批 / batch 经验 / rollout 来进行多次训练,即:
- 假设某次策略更新完毕后,得到策略 $\pi_{old}$;
- 使用 $\pi_{old}$ 与环境进行交互,得到一批经验数据(状态价值、优势、回报);
- 将此回合数据重复使用 $k$ 次:将其输入 $\pi_{old}$,更新得到 $\pi_{\theta_0}$;再将同一批数据输入 $\pi_{\theta_0}$,更新得到 $\pi_{\theta_1}$;以此类推,$k$ 次更新,得到 $\pi_\theta$。此过程即 Off-Policy $\Rightarrow$ 产出数据的策略 ($\pi_{old}$) 和基于这批数据更新的策略 ($\pi_{\theta_0}, \dots, \pi_{\theta_{k-1}}, \pi_\theta$) 不是同一个;
- $k$ 次更新后,令 $\pi_{old} = \pi_\theta$,重复直至达到设定停止条件。
但在($k$ 次的)训练过程中,策略实际已经发生变化,采样出来分布也变化,即:
存在两个分布 $p(x)$ 和 $q(x)$,无法直接从 $p(x)$ 采样时,可以通过下面的方式描述 $x \sim p(x)$ 下 $f(x)$ 的期望:
$$ \mathbb{E}_{x \sim p(x)}[f(x)] = \int \frac{p(x)}{q(x)} f(x) q(x) dx = \mathbb{E}_{x \sim q(x)}\left[\frac{p(x)}{q(x)} f(x)\right] $$先前的策略梯度为:
$$ \nabla J(\pi_\theta) = \mathbb{E}_t[A_\pi(s_t, a_t) \nabla \log \pi_\theta(a_t|s_t)] $$此时的策略梯度为:
$$ \nabla J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_{\theta_{\mathrm{old}}}}\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{old}(a_t|s_t)} A_\pi(s_t, a_t) \nabla \log \pi_\theta(a_t|s_t)\right] $$即从 $\pi_{old}$ 中采样数据,使用数据来训练 $\pi_\theta$。
理论上优势 $A_\pi$ 由于策略变化也会发生变化,但希望重复使用该经验,只能希望策略变化不太大,即 $\pi_\theta$ 和 $\pi_{old}$ 相差不大(是否因此引入了 KL Loss?)。
GAE (Generalized Advantage Estimation)
$\mathrm{TD\_Error}$ 是 Advantage 的无偏估计,但在训练开始阶段,$V_\pi$ 可能无法刻画真实的状态价值,可以选择少信任 $V_\pi$ 的计算结果,将 $V_\pi(s_{t+1})$ 展开:
$$ r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t) = -V_\pi(s_t) + \sum_{l=0}^{\infty} \gamma^l r_{t+l} $$其中 $r_t, r_{t+1}, r_{t+2}, \dots$ 均为某次采样得到的即时奖励数据。若 $V_\pi$ 不准,可以信任实际采样结果,至少不会对优势函数的估计出现偏差。
GAE 基于 $\mathrm{TD}(\lambda)$ 的思想,通过结合多步 TD 估计来平衡偏差与方差。具体而言,GAE 定义了一个连续的优势估计:
$$ A_t^{GAE} = \sum_{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l} $$ $$ \delta_t = r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t) $$- $\lambda \to 0$:$A_t^{GAE}$ 退化成单步 TD 误差 $r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t)$;
- $\lambda \to 1$:$A_t^{GAE}$ 变为 $-V_\pi(s_t) + \sum_{l=0}^{\infty} \gamma^l r_{t+l}$,此时 GAE 使用整个奖励序列来估计优势。
新的策略梯度为:
$$ \nabla J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_{\theta_{old}}}\left[\frac{\pi_\theta(a_t|s_t)}{\pi_{old}(a_t|s_t)} A_\pi^{GAE}(s_t, a_t) \nabla \log \pi_\theta(a_t|s_t)\right] $$由于 $ \nabla f(x) = f(x) \nabla \log f(x)$,即 $ \nabla \pi_\theta = \pi_\theta \nabla \log \pi_\theta$:
$$ \nabla J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_{\theta_{old}}}\left[\frac{\nabla \pi_\theta(a_t|s_t)}{\pi_{old}(a_t|s_t)} A_{\pi}^{GAE}(s_t, a_t)\right] $$Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!