Prompt-OIRL: Query-Dependent Prompt Optimization with Offline Inverse RL
Motivation
No prompt is perfect that works for all queries. The optimal prompt is query-dependent.
Query-Dependent Prompt Optimization
zero-shot prompting 更多关注寻找在 distribution-level 上有效的 prompts 而非 instance-level。
Challenge 1: Inference Time Evaluation is Hard
如何在 inference 时评估当前 prompt 的有效性?特别是 query 的 true answer 未知时。
Challenge 2: Online Prompt Evaluation and Optimization is Expensive
以往做法:验证提出的 prompt 的有效性 需要在多个数据集和 LLMs 上实验。
Solution: Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL
Query-Dependent Prompting
Queries and Answers. 用自然语言表达的 Task $x \in \mathcal{X} = \mathcal{V}^{\infty}$,其中 $\mathcal{V}$ 是词汇表。假设每个 query $x$ 存在一个期望 answer $y^* \in \mathcal{Y}$。
Language Model. $l: \mathcal{X} \to \mathcal{Y}$,向语言模型中输入 $x$,得到答案 $\hat{y} = l(x)$。假设这些答案可以被一个指标进行量化 $r: \mathcal{Y} \times \mathcal{Y} \to \mathbb{R}$,例如存在可获取的 golden labels $r(y^*, \hat{y}) = \mathbb{1}\{\hat{y} = y^*\}$。
Prompting. $\pi: \mathcal{X} \to \mathcal{X}$,将原始 query $x$ 映射到修改后的 prompted query $\pi(x)$,$\hat{y} = l(\pi(x))$。
Objective. 给定数据集 $\mathcal{D} = \{x^{(i)}, y^{*(i)}\}_{i \in [N]}$,query-agnostic zero-shot prompt optimization 的优化目标是寻找 distributional optimal prompt $\bar{\pi}^*$,最大化答案的期望质量。
寻求 single prompt 实现数据集上的性能:
$$ \bar{\pi}^{*} = \arg\max_{\pi} \mathbb{E}_{(x^{(i)}, y^{*(i)}) \sim \mathcal{D}} \left[ r\left(y^{*(i)}, \ell(\pi(x^{(i)}))\right) \right] $$使用 query-dependent approach 调整训练目标:
$$ \pi^{*} = \arg\max_{\pi} \, r\left(y^{*(i)}, \ell(\pi(x^{(i)}))\right) $$寻求 different prompts for different queries,因此 $\pi^*$ 应该优于 $\bar{\pi}^*$:
$$ \mathbb{E}_{(x^{(i)}, y^{*(i)}) \sim \mathcal{D}} \left[ r\left(y^{*(i)}, \ell(\pi^{*}(x^{(i)}))\right) \right] \ge \mathbb{E}_{(x^{(i)}, y^{*(i)}) \sim \mathcal{D}} \left[ r\left(y^{*(i)}, \ell(\bar{\pi}^{*}(x^{(i)}))\right) \right] $$Prompt-OIRL: Prompting with Offline Inverse RL
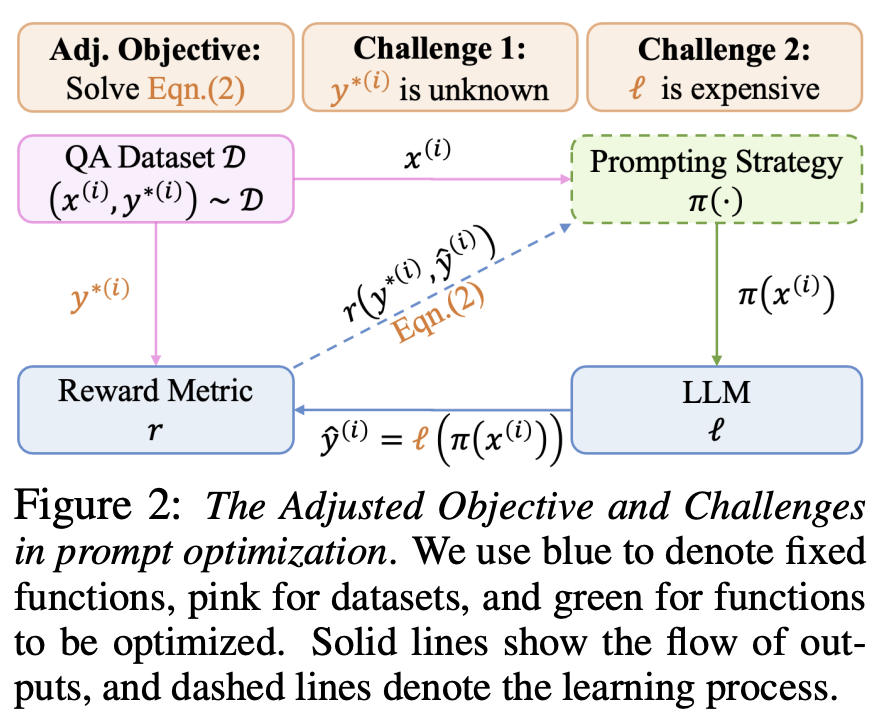
Challenge 1: inability to compute rewards during inference.
Challenge 2: the necessity for extensive interactions with LLMs.
传统 RL:稀疏的 trajectory-level feedback and huge overheads of interaction with LLMs,同时在 inference phase 没有确定性标签。
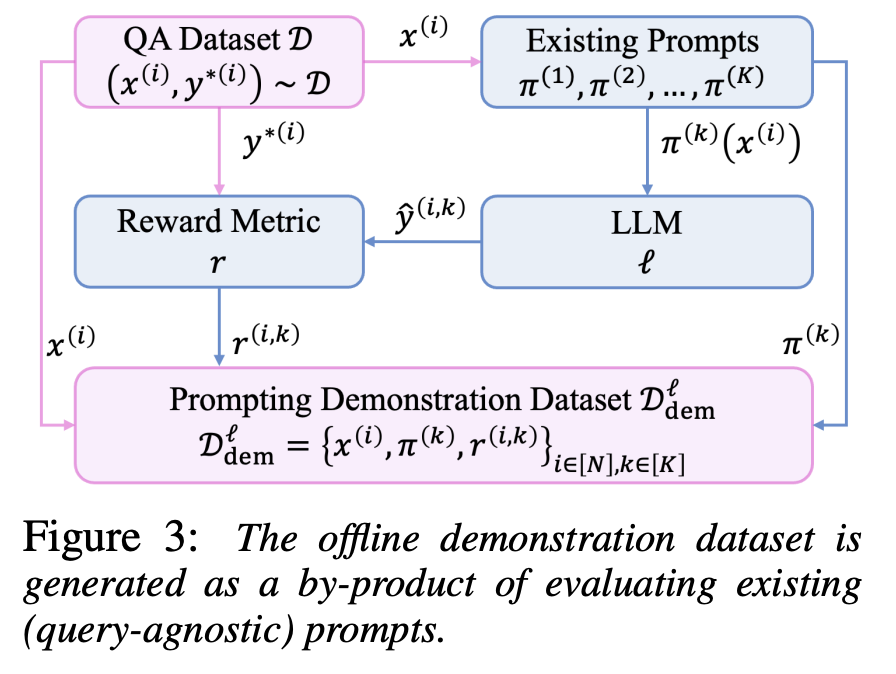
Step 1: Existence of Offline Prompt Demonstrations
$$ \mathcal{D}^{\ell}_{\mathrm{dem}} = \left\{ x^{(i)},\, \pi^{(k)},\, r^{(i,k)} = r\!\left(y^{*(i)},\, \ell(\pi^{(k)}(x^{(i)}))\right) \right\}_{i \in [N],\, k \in [K]} $$prompt-alignment demonstration datasets 通过评估现有 prompts,其中奖励受语言模型影响。
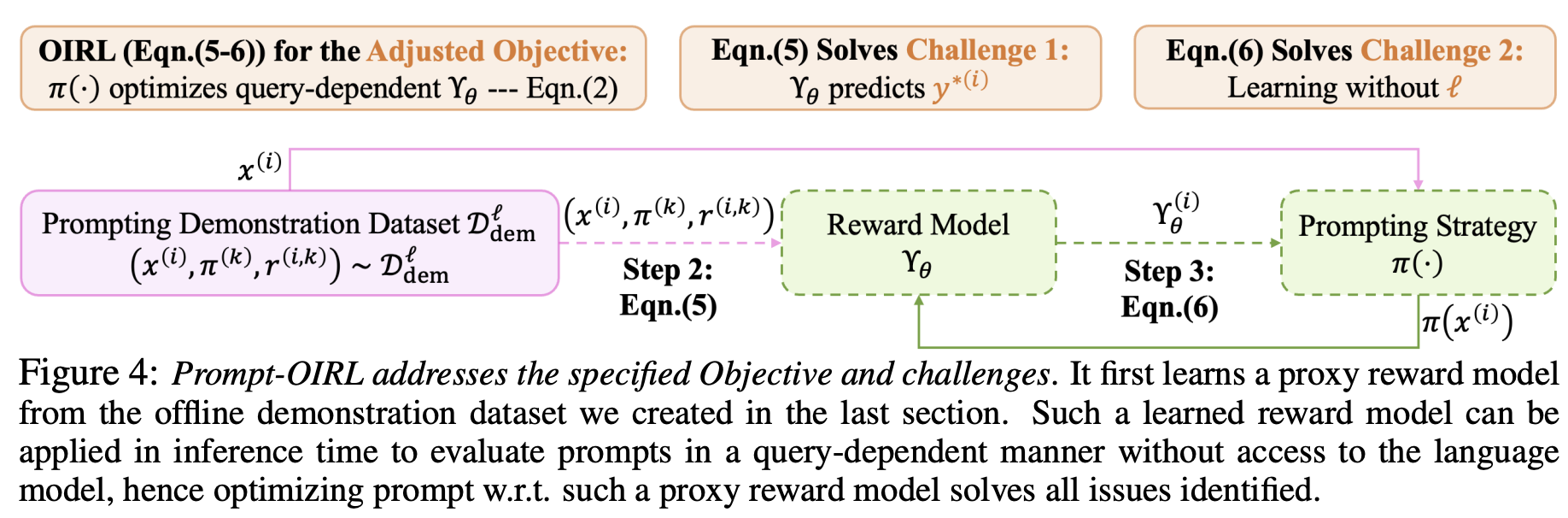
Step 2: Offline Reward Modeling — Inverse RL without an Environment
当前问题:
- 奖励指标是语言模型 $l$ 上的一个函数,成本高;
- 计算奖励需要获取真实答案 $y^*$,但在 inference time 通常无法获取。
引入参数化的 proxy reward model,是 query $x$ 和 prompt $\pi$ 的函数,记为 $r_\theta(x, \pi(x))$。
数学推理任务中的奖励信号是二元的,可以被视为分类任务,预测输入语言模型后能否产生正确答案:
$$ \mathcal{L}_{\mathrm{CE}}(\theta; \mathcal{D}^{\ell}_{\mathrm{dem}}) = - \mathbb{E}_{i \in [N],\, k \sim [K]} \left[ r^{(i,k)} \log \sigma\!\left(r^{(i,k)}_{\theta}\right) + \left(1 - r^{(i,k)}\right) \log\!\left(1 - \sigma\!\left(r^{(i,k)}_{\theta}\right)\right) \right] $$使用 $x$ 和 $\pi$ 的 embedding 作为 reward model 的输入。
Step 3: Offline Prompt Optimization with the Learned Reward Model
$$ \pi^{*} = \arg\max_{\pi}\, r_{\theta}(x, \pi(x)) \;\approx\; \arg\max_{\pi}\, r\!\left(y^{*}, \ell(\pi(x))\right) $$使用通用语言模型生成 batch 候选 prompts,利用学习到的 RM 选择最好的一个。
Reference
[1] Sun, H., Hüyük, A., & van der Schaar, M. (2024). Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL. ICLR 2024.
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!