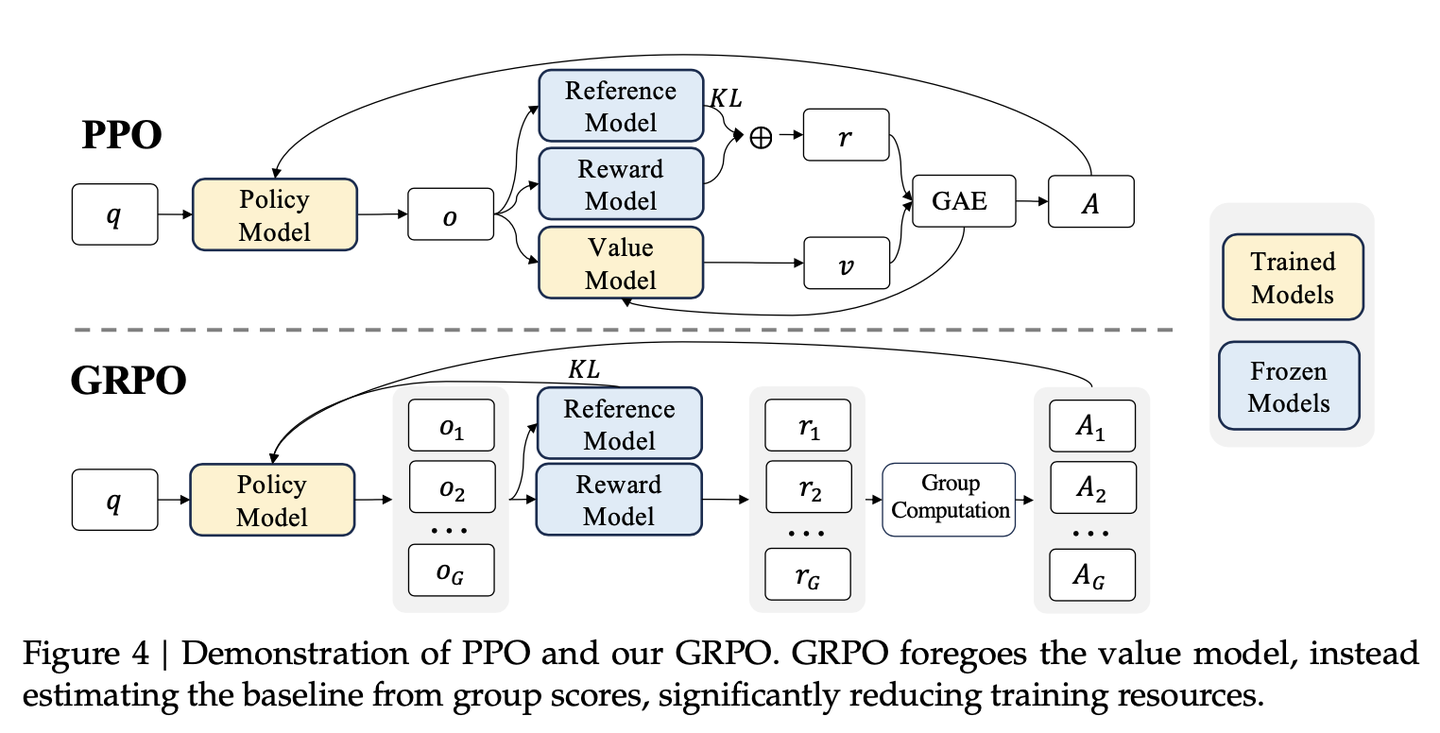
GRPO: Group Relative Policy Optimization
PPO 的缺点:
- 需要训练一个与 Policy Model 大小相当的 Value Model,带来巨大的内存与计算负担。
- LLM 上下文中,仅最后一个 token 被奖励模型打分,使得训练一个在每个 token 上都准确的 Value Function 很困难。
Optimization Objective
GRPO 避免 PPO 用额外的价值函数近似,使用同一问题下多个采样输出的平均奖励作为基线。
给定每个问题 $q$,GRPO 从旧策略 $\pi_{\theta_{old}}$ 中采样出一组 rollout $\{o_1, o_2,...,o_G\}$,最大化目标函数,优化 Policy Model:
$$ \begin{aligned} \mathcal{J}_{GRPO}(\theta)=&\,\mathbb{E}_{q\sim P(Q),\,\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)}\Bigg[\frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\Big\{\\ &\min\Big[\frac{\pi_\theta(o_{i,t}|q,o_{i,\lt t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,\lt t})}\hat{A}_{i,t},\,\text{clip}\Big(\frac{\pi_\theta(o_{i,t}|q,o_{i,\lt t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,\lt t})},1-\epsilon,1+\epsilon\Big)\hat{A}_{i,t}\Big]\\ &-\beta\,\mathbb{D}_{KL}[\pi_\theta\|\pi_{ref}]\Big\}\Bigg] \end{aligned} $$其中各元素:
- $\mathbb E[q\sim P(Q),\{o_i\}_{i=1}^G\sim \pi_{\theta_{old}}(O|q)]$:对问题 $q$ 从问题分布 $P(Q)$ 中采样,以及 rollout 组 $o_i$ 从旧策略 $\pi_{\theta_{old}}$ 中采样的期望。
- $\pi_{\theta}(o_{i,t}|q,o_{i,\lt t})$:当前策略模型 $\pi_\theta$ 在给定问题 $q$ 和 rollout 的前 $t$ 个 token $o_{i,\lt t}$ 的条件下,生成当前 token $o_{i,t}$ 的概率。
- $\pi_{\theta_{old}}(o_{i,t}|q,o_{i,\lt t})$:旧策略模型 $\pi_{\theta_{old}}$ 下生成当前 token 的概率。
- $\hat A_{i,t}$:基于组内相对奖励计算的优势函数。
- $\epsilon$:裁剪超参数,用于限制策略更新的幅度。
- $\beta$:KL 散度惩罚项系数。
- $D_{KL}[\pi_\theta\|\pi_{ref}]$:当前策略 $\pi_\theta$ 和参考策略 $\pi_{ref}$ 间的 KL 散度。应该使用无偏估计 estimator 计算,目的:减少 KL 散度计算的高方差(参见 Schulman: Approximating KL Divergence): $$ D_{KL}[\pi_\theta\|\pi_{ref}]=\frac{\pi_{ref}(o_{i,t}|q,o_{i,\lt t})}{\pi_{\theta}(o_{i,t}|q,o_{i,\lt t})} - \log \frac{\pi_{ref}(o_{i,t}|q,o_{i,\lt t})}{\pi_{\theta}(o_{i,t}|q,o_{i,\lt t})}-1 $$
Advantage Function
GRPO 无 Critic 模型,利用组内相对奖励计算优势。
对于每个问题 $q$,GRPO 从旧策略 $\pi_{\theta_{old}}$ 中采样一组 $\{o_1,o_2,...,o_G\}$,使用奖励模型对这些输出进行评分,得到相应奖励 $r=\{r_1,r_2,...,r_G\}$。通过减去组平均值并除以组标准差来归一化奖励:
$$ \hat A_{i,t}=\tilde r_i=\frac{r_i-\text{mean}(r)}{\text{std}(r)} $$⇒ 结果监督 Outcome Supervision:只对结果给出奖励分数。
过程监督 Process Supervision:仅在末尾提供奖励的结果监督在复杂数学任务中可能不足,可在每个推理步骤的末尾提供奖励,更细粒度地指导策略学习。对于每个问题 $q$ 和一组采样 $\{o_1,o_2,...,o_G\}$,使用 PRM 对每个输出的推理步骤评分,得到步骤奖励:
$$ R=\{\{r_1^{index(1)},...,r_1^{index(K_1)}\},...,\{r_G^{index(1)},...,r_G^{index(K_G)}\}\} $$其中 $index(j)$ 表示第 $j$ 步结束 token 的索引,$K_i$ 是第 $i$ 个输出的思维链的总步骤数。
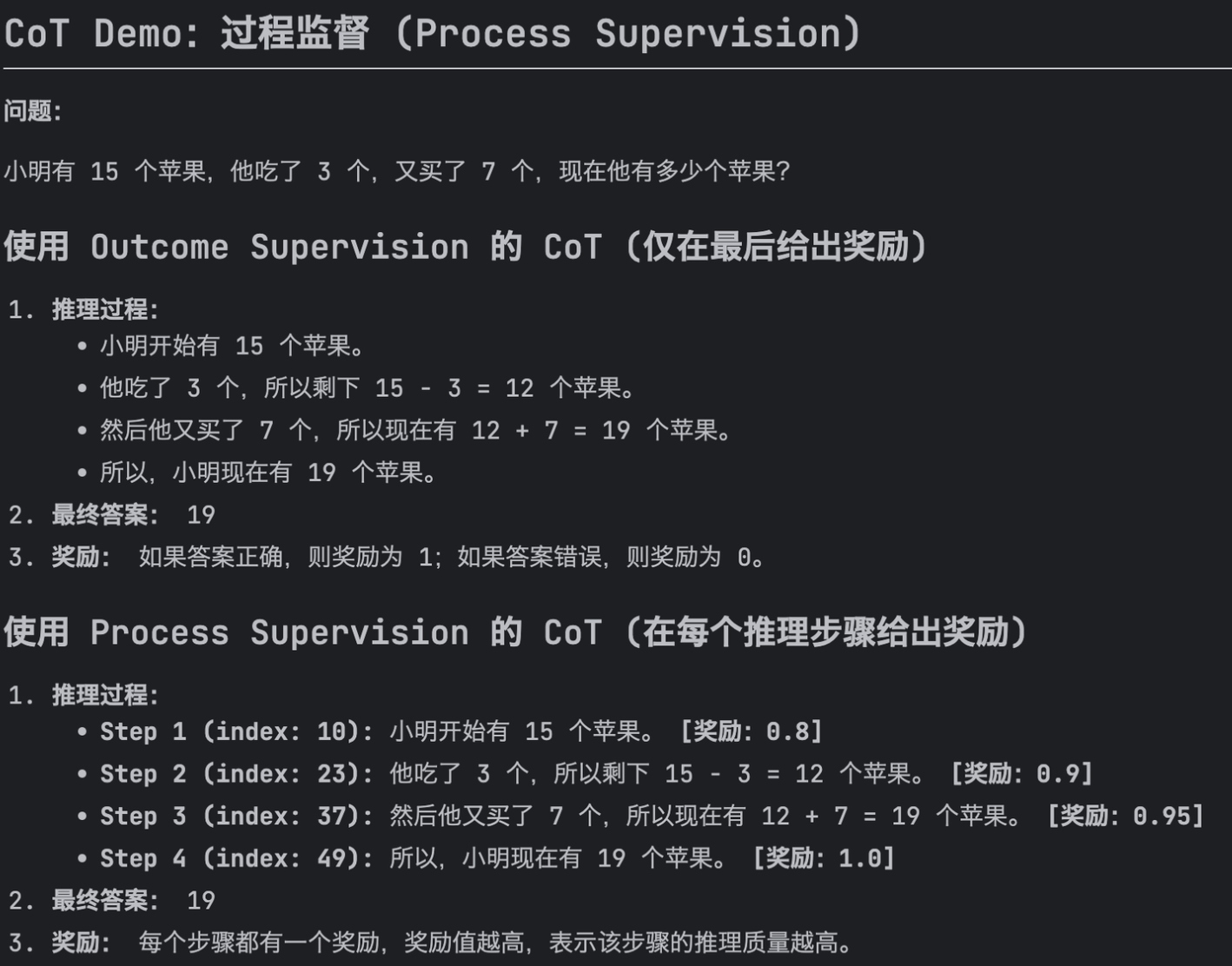
每个 token 的优势函数 $\hat A_{i,t}$ 计算为该 token 之后所有步骤的奖励之和:
$$ \tilde r_i^{index(j)}=\frac{r_i^{index(j)}-\text{mean}(r)}{\text{std}(r)} $$ $$ \hat A_{i,t}=\sum_{index(j)\ge t}\tilde r_i^{index(j)} $$RM Dataset
自动化标注方法,方法来源:MATH-SHEPHERD。将一个推理步骤的质量定义为推导出正确答案的潜力,通过补全和估计两个步骤实现自动标注。
- 补全:给定推理步骤 $s_i$,使用补全器(completer)从该步骤开始,完成 $N$ 个后续的推理过程,表示为 $(s_{i+1,j},...,s_{K_j,j},a_j)_{j=1}^N$。其中 $s_{i+1,j},...,s_{K_j,j},a_j$ 表示第 $j$ 个完成推理过程的后续步骤,$a_j$ 表示第 $j$ 个完成推理过程的解码答案,$K_j$ 表示第 $j$ 个完成推理过程的总步骤数。可以通过完成的推理过程,评估步骤 $s_i$ 的潜力。
- 估计:基于补全得到的 $N$ 个完成推理过程的答案,估计步骤 $s_i$ 的质量 $y_{s_i}$:
- 硬估计 Hard Estimation:存在一个答案 $a_j$ 等于正确答案 $a^*$,认为步骤 $s_i$ 好,将标签设置为 1,否则为 0。
- 软估计 Soft Estimation:将步骤 $s_i$ 质量定义为答案等于正确答案 $a^*$ 的频率: $$ y_{s_i}^{SE}=\frac{\sum_{j=1}^N\mathbb{I}(a_j=a^*)}{N} $$


GRPO 优点
- 无需额外的价值函数:组内平均奖励作为 baseline,无需额外的价值函数,减少内存和计算负担。
- 原先的 Advantage:$R-V(s)$
- 现在的 Advantage:$R-\text{mean}(r)$
- 与 Reward Model 的比较性质对齐:组内平均奖励计算优势函数,与 RM 在同一问题的不同输出之间进行比较的性质相符。
- KL 惩罚在损失函数中:将训练策略 $\pi_\theta$ 和参考策略 $\pi_{ref}$ 间的 KL 散度加到损失中,而不是如 PPO 将 KL 加在奖励中,避免了复杂化的 $\hat A_{i,t}$ 的计算。
理解 LLM 多种学习方法的统一范式
训练中模型参数 $\theta$ 的梯度可以从以下三个维度统一描述:
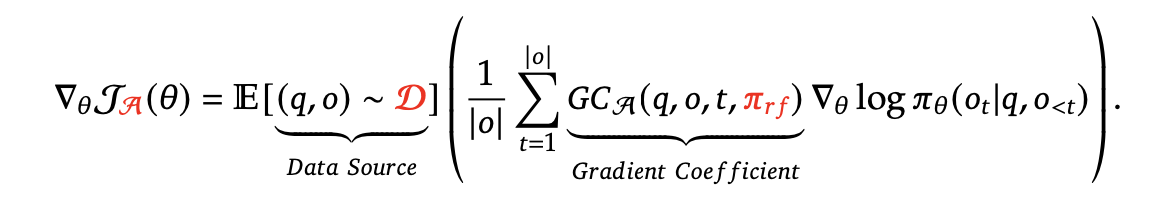
- 数据源 $\mathcal{D}$:决定训练数据。
- 奖励函数 $\pi_{rf}$:训练过程奖励信号的来源。
- 梯度计算算法 $\mathcal A$:将训练数据和奖励信号处理为梯度系数 $GC$,决定数据的惩罚或强化幅度。
1) SFT — Supervised Fine-tuning
- 数据源:SFT 数据集 $q,o\sim P_{sft}(Q,O)$。
- 奖励函数:SFT 数据为人工挑选 / 模型或方法筛选,视作奖励规则,所有数据均视为正向奖励。
- 梯度计算算法: $$ \mathcal J_{SFT}(\theta)=\mathbb{E}_{q,o\sim P_{sft}(Q,O)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\log \pi_\theta(o_t|q,o_{\lt t})\right] $$ $$ \nabla_\theta\mathcal J_{SFT}(\theta)=\mathbb{E}_{q,o\sim P_{sft}(Q,O)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\nabla_\theta\log \pi_\theta(o_t|q,o_{\lt t})\right] $$ 此时 $GC$ 恒等于 1。
2) RFT — Rejection Sampling Fine-tuning
从经过 SFT 的 LLM 中采样多个输出,然后利用具有正确答案的 sample 进行训练。
- 数据源:采样 $\pi_{sft}$ 回答,$q\sim P_{sft}(Q),~o\sim\pi_{sft}(O|q)$。
- 奖励函数:基于规则 $\mathbb I(o)$,即正确与否。
- 梯度计算方法: $$ \mathcal{J}_{RFT}(\theta)=\mathbb E_{q\sim P_{sft}(Q),o\sim\pi_{sft}(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb I(o)\log\pi_{\theta}(o_t|q,o_{\lt t})\right] $$ $$ \nabla_\theta\mathcal J_{RFT}(\theta)=\mathbb E_{q\sim P_{sft}(Q),o\sim\pi_{sft}(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb I(o)\nabla_\theta\log\pi_{\theta}(o_t|q,o_{\lt t})\right] $$ 即 $GC_{RFT}(q,o,t)=\mathbb I(o)=\begin{cases}1 & \text{correct answer}\\ 0 & \text{incorrect answer}\end{cases}$
3) DPO — Direct Preference Optimization
无需 reward model,使用 pair-wise 的 DPO loss 对 SFT 模型采样的增强输出微调。
- 数据源:采样自 $\pi_{sft}$ 的回答,包含正负样本 $q\sim P_{sft}(Q);~o^+,o^-\sim\pi_\theta(O|q)$。
- 奖励函数:对于数学题,基于规则,即正确与否。
- 梯度计算算法:
优化目标
$$ \mathcal{J}_{DPO}(\theta)=\mathbb E_{q\sim P_{sft}(Q);~o^+,o^-\sim\pi_\theta(O|q)}\,\log\sigma\!\left(\beta\Big(\tfrac{1}{|o^+|}\sum_{t=1}^{|o^+|}\log\tfrac{\pi_\theta(o^+_t|q,o^+_{\lt t})}{\pi_{ref}(o^+_t|q,o^+_{\lt t})}-\tfrac{1}{|o^-|}\sum_{t=1}^{|o^-|}\log\tfrac{\pi_\theta(o^-_t|q,o^-_{\lt t})}{\pi_{ref}(o^-_t|q,o^-_{\lt t})}\Big)\right) $$目标函数梯度
$$ \nabla_{\theta} J_{\mathrm{DPO}}(\theta) = \mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, o^{+},o^{-}\sim \pi_{\mathrm{sft}}(O|q)} \left[ \tfrac{1}{|o^{+}|} \sum_{t=1}^{|o^{+}|} GC_{\mathrm{DPO}}(q,o,t)\, \nabla_{\theta}\log \pi_{\theta}(o_t^{+}\mid q,o_{\lt t}^{+}) - \tfrac{1}{|o^{-}|} \sum_{t=1}^{|o^{-}|} GC_{\mathrm{DPO}}(q,o,t)\, \nabla_{\theta}\log \pi_{\theta}(o_t^{-}\mid q,o_{\lt t}^{-}) \right] $$ 即 $GC_{DPO}(q,o,t)=\sigma\!\left(\beta\log\tfrac{\pi_\theta(o^+_t|q,o^+_{\lt t})}{\pi_{ref}(o^+_t|q,o^+_{\lt t})} - \beta\log\tfrac{\pi_\theta(o^-_t|q,o^-_{\lt t})}{\pi_{ref}(o^-_t|q,o^-_{\lt t})}\right)$
DPO 梯度推导(简记 $R(o)=\frac{1}{|o|}\sum_t (\log\pi_\theta - \log\pi_{ref})$):
令:
R(o) = (1/|o|) * sum(log(π_θ(o_t|q,o_<t)) - log(π_ref(o_t|q,o_<t)))
即每个序列的对数似然比的平均值
则目标函数可以写为:
J_DPO(θ) = E[logsigmoid(β(R(o+) - R(o-)))]
1. logsigmoid 的导数:
d/dx(logsigmoid(x)) = sigmoid(-x)
2. 链式法则:
∇_θ J_DPO = E[sigmoid(-β(R(o+) - R(o-))) * β * ∇_θ(R(o+) - R(o-))]
3. 对 R(o) 求导:
∇_θ R(o) = (1/|o|) * sum(∇_θ log(π_θ(o_t|q,o_<t)))
4. 最终梯度:
∇_θ J_DPO = E[sigmoid(-β(R(o+) - R(o-))) * β *
((1/|o+|) * sum(∇_θ log(π_θ(o_t+|q,o_<t+))) -
(1/|o-|) * sum(∇_θ log(π_θ(o_t-|q,o_<t-))))]
4) Online RFT — Online Rejection Sampling Fine-tuning
使用 SFT model $\pi_{sft}$ 初始化策略模型 $\pi_\theta$。与 RFT 的区别:通过使用从实时策略模型 $\pi_\theta$ 中采样的增强输出进行微调。
- 数据源:采样自 $\pi_\theta$ 的回答,$q\sim P_{sft}(Q),~o\sim\pi_\theta(O|q)$。
- 奖励函数:基于规则 $\mathbb I(o)$。
- 梯度计算方法: $$ \nabla_\theta\mathcal J_{OnlineRFT}(\theta)=\mathbb E_{q\sim P_{sft}(Q),o\sim\pi_\theta(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb I(o)\nabla_\theta\log\pi_\theta(o_t|q,o_{\lt t})\right] $$ 即 $GC_{OnlineRFT}(q,o,t)=\mathbb I(o)$。
5) PPO — Proximal Policy Optimization
从实时策略模型 $\pi_\theta$ 中采样输出,然后用这些数据优化模型。
- 数据源:$q\sim P_{sft}(Q),~o\sim\pi_\theta(O|q)$。
- 奖励函数:Reward Model 给出。
- 梯度计算方法:
优化目标(完整形式)
$$ J_{\mathrm{PPO}}(\theta)=\mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, o \sim \pi_{\theta_{\mathrm{old}}}(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\min\!\left(\frac{\pi_\theta(o_t \mid q,o_{\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_t \mid q,o_{\lt t})}A_t,\;\operatorname{clip}\!\left(\frac{\pi_\theta(o_t \mid q,o_{\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_t \mid q,o_{\lt t})},1-\epsilon,1+\epsilon\right)A_t\right)\right] $$简化形式(去掉 Clip)
$$ J_{\mathrm{PPO}}(\theta)=\mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, o \sim \pi_{\theta_{\mathrm{old}}}(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}\frac{\pi_\theta(o_t \mid q,o_{\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_t \mid q,o_{\lt t})}A_t\right] $$目标函数梯度
$$ \nabla_\theta J_{\mathrm{PPO}}(\theta)=\mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, o \sim \pi_{\theta_{\mathrm{old}}}(O|q)}\left[\frac{1}{|o|}\sum_{t=1}^{|o|}A_t\,\nabla_\theta \log \pi_\theta(o_t \mid q,o_{\lt t})\right] $$ 即 $GC_{PPO}(q,o,t,\pi_{\theta_{rm}})=A_t$,其中 $A_t$ 是使用 GAE 计算得到的优势,需要使用奖励 $\{r_{\ge t}\}$ 和 Critic 模型 $V_\psi$。
6) GRPO — Group Relative Policy Optimization
从实时策略模型 $\pi_\theta$ 采样一组数据。
- 数据源:$q\sim P_{sft}(Q),~\{o_i\}_{i=1}^G\sim\pi_\theta(O|q)$。
- 奖励函数:由 Reward Model 给出。
- 梯度计算方法:
优化目标
$$ J_{\mathrm{GRPO}}(\theta)=\mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, \{o_i\}_{i=1}^{G}\sim\pi_{\theta_{\mathrm{old}}}(O|q)}\!\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\!\left(\frac{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}\mid q,o_{i,\lt t})}\hat{A}_{i,t}-\beta\!\left(\frac{\pi_{\mathrm{ref}}(o_{i,t}\mid q,o_{i,\lt t})}{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}-\log\frac{\pi_{\mathrm{ref}}(o_{i,t}\mid q,o_{i,\lt t})}{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}-1\right)\right)\right] $$目标函数梯度
$$ \nabla_\theta J_{\mathrm{GRPO}}(\theta)=\mathbb{E}_{q \sim P_{\mathrm{sft}}(Q),\, \{o_i\}_{i=1}^{G}\sim\pi_{\theta_{\mathrm{old}}}(O|q)}\!\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\!\left(\frac{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}\mid q,o_{i,\lt t})}\hat{A}_{i,t}+\beta\!\left(\frac{\pi_{\mathrm{ref}}(o_{i,t}\mid q,o_{i,\lt t})}{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}-1\right)\right)\nabla_\theta\log \pi_\theta(o_{i,t}\mid q,o_{i,\lt t})\right] $$ 即 $GC_{\mathrm{GRPO}}(q,o,t,\pi_{\theta_{\mathrm{rm}}})=\dfrac{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}\mid q,o_{i,\lt t})}\hat{A}_{i,t}+\beta\Big(\dfrac{\pi_{\mathrm{ref}}(o_{i,t}\mid q,o_{i,\lt t})}{\pi_\theta(o_{i,t}\mid q,o_{i,\lt t})}-1\Big)$
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!