CS336 Assignment 1: Transformers Language Model Architecture
Feb. 03, 2026 · Qiyao Wang
Transformer Basics
语言模型的输入是经过 tokenizer 分词后的整数 token IDs 序列 (batch化),形状为 (batch_size, sequence_length),输出为正则化的词典中 token 的概率分布,形状为(batch_size, sequence_length, vocab_size)。训练语言模型时,计算输出概率分布和实际标签分布之间的交叉熵损失(cross-entropy loss)。在推理阶段,则使用当前时间步的下一个 token 的分布来采样解码得到预测 token,之后该 token 又会加入输入序列中继续预测下一时间步的 token。
基于Transformer架构的语言模型主要包括以下几个组件和步骤(见图1):给定 token IDs 序列,经过 Embedding Layer 将整数的 token ID 映射成稠密的向量,之后传入 num_layers 层的 Transformer blocks,取最后一层 Transformer block 的输出,通过一个 FFN(一般称为 LM head)来产生词典级别的输出 token 概率分布,之后进行解码采样得到预测的 token。
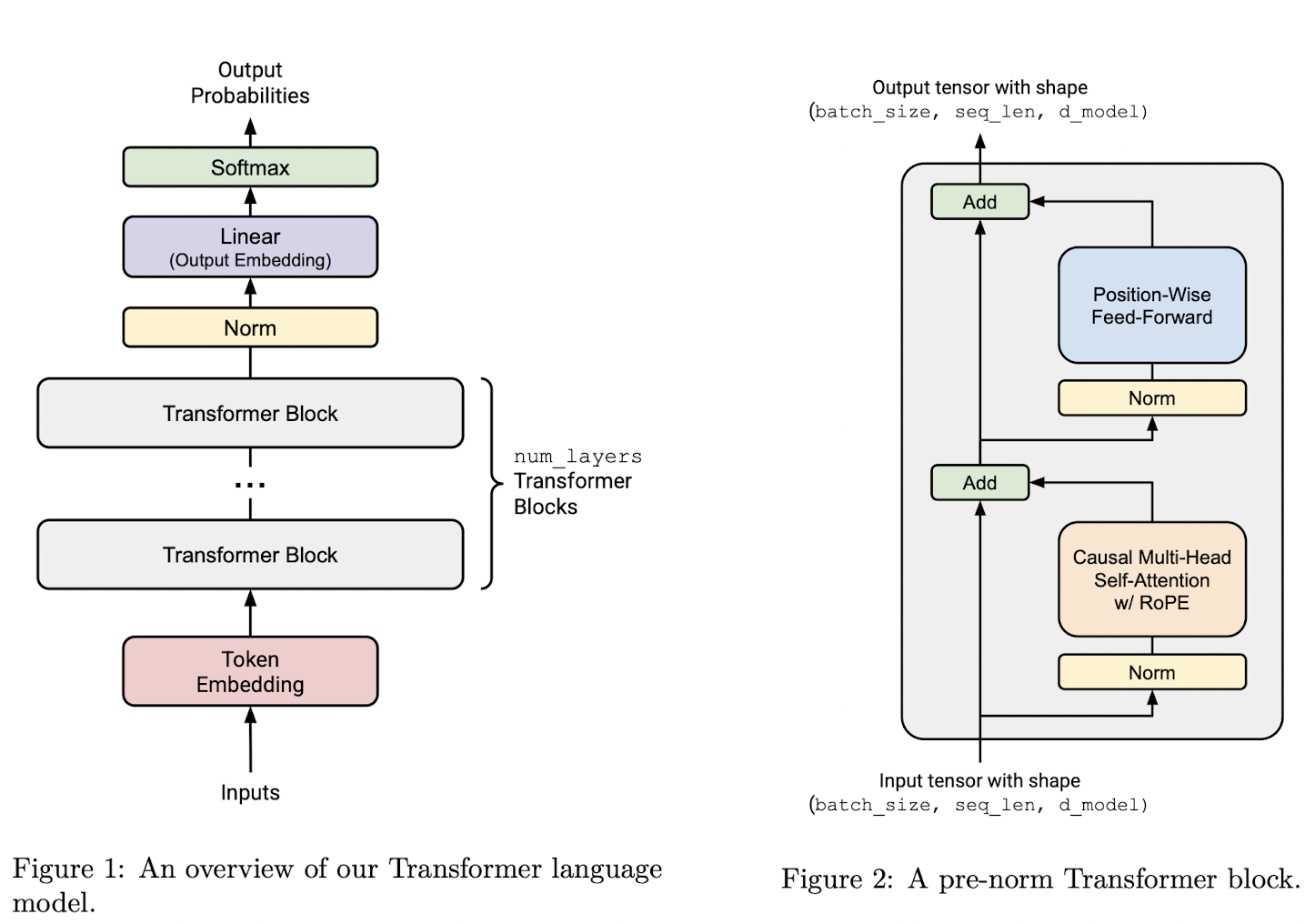
Token Embeddings: (batch_size, sequence_length) $\to$ (batch_size, sequence_length, d_model).
发生在每个Transformer Block 中的 Attention 计算之前的 Normalization,Pre-norm Transformer Block: (batch_size, sequence_length, d_model) $\to$ (batch_size, sequence_length, d_model).
Output Normalization 会在最后一个 Transformer Block 后进行 Layer Normalization。
Efficient Computation
Transformer 架构中一般进行 batch-level 的并行计算。在具体分析的时候主要关注下面三个元素:
- Elements of a batch: 每一次 forward computation 在一个 batch_size 大小的数据中进行,
forward依次作用到 batch 中的每一个数据中。 - Sequence length: 对于 RMSNorm 和 Feed-forward 等 point-wise 的位置无关操作,在序列中每个位置的处理都一样。
- Attention heads: 注意力操作可以并行,也是 Transformer 可以并行的基础之一,并且可以基于 batch 来处理多头注意力操作。
(batch_size, sequence_length, d_model),在其上进行 batched vector-matrix multiply,矩阵为 A,形状是 (d_model, d_model),则 D @ A 会进行 batched matrix multiply,其中 (batch_size, sequence_length) 是批处理的。
使用 einsum notation 进行更方便的批处理。PyTorch 中是 torch.einsum,与框架无关的库是 einops (本次使用)和 einx。
主要有两个关键的操作:
- einsum: 可以对 tensor 做任意的操作,见下面的表格的总结。
- rearrange: 可以重新排列、连接和拆分张量的维度。
| 操作类型 | einsum 表达式示例 | 张量形状示例 | 等价常见操作 | 说明 |
|---|---|---|---|---|
| 转置 / 维度重排 | einsum("ij->ji", A) |
A: (i, j) | A.T, permute |
只改变维度顺序,不做数值计算 |
| 求和(Reduce) | einsum("ij->i", A) |
A: (i, j) | A.sum(dim=1) |
消除未出现在输出中的维度 |
| 逐元素乘法 | einsum("ij,ij->ij", A, B) |
A,B: (i, j) | A * B |
对应元素相乘 |
| 内积 / 点积 | einsum("i,i->", x, y) |
x,y: (i) | torch.dot |
输出标量 |
| 外积 | einsum("i,j->ij", x, y) |
x:(i), y:(j) | outer |
生成高阶张量 |
| 矩阵乘法 | einsum("ij,jk->ik", A, B) |
A:(i,j), B:(j,k) | matmul |
经典线性代数操作 |
| 批量矩阵乘 | einsum("bij,bjk->bik", A, B) |
A,B:(b,i,j) | bmm |
每个 batch 独立计算 |
| Trace(迹) | einsum("ii->", A) |
A:(i,i) | trace |
对角线求和 |
| Attention 核心计算 | einsum("bhtd,bhsd->bhts", Q, K) |
Q,K:(b,h,t,d) | Q @ Kᵀ | Transformer 中的相似度计算 |
| 线性层 / Token Mixing | einsum("btc,cd->btd", X, W) |
X:(b,t,c), W:(c,d) | Linear / MatMul | 特征维度线性变换 |
| 多操作融合 | einsum("bct,td->bc", X, W) |
X:(b,c,t) | permute + matmul + sum | 一行完成多步计算 |
| 操作类型 | rearrange 表达式示例 | 输入形状示例 | 输出形状 | 等价常见操作 | 说明 |
|---|---|---|---|---|---|
| 转置 / 维度重排 | rearrange(x, "b c h w -> b h w c") |
(b, c, h, w) | (b, h, w, c) | permute |
仅改变维度顺序,不改数值 |
| 合并维度(merge) | rearrange(x, "b t d -> b (t d)") |
(b, t, d) | (b, t·d) | reshape |
将多个维度合并成一个 |
| 拆分维度(split) | rearrange(x, "b (h d) -> b h d", h=8) |
(b, h·d) | (b, h, d) | view |
需要显式指定拆分尺寸 |
| Flatten | rearrange(x, "b c h w -> b (c h w)") |
(b, c, h, w) | (b, c·h·w) | flatten |
常用于 CNN → Transformer |
| Unflatten | rearrange(x, "b (h w) c -> b c h w", h=32) |
(b, h·w, c) | (b, c, h, w) | view |
恢复空间结构 |
| Patch 划分(ViT) | rearrange(x, "b c (h p1) (w p2) -> b (h w) (c p1 p2)", p1=16, p2=16) |
(b, c, H, W) | (b, num_patches, patch_dim) | 手写切块 | Vision Transformer 核心操作 |
| 多头拆分(Heads) | rearrange(x, "b t (h d) -> b h t d", h=8) |
(b, t, h·d) | (b, h, t, d) | reshape + permute | Attention 预处理 |
| 多头合并 | rearrange(x, "b h t d -> b t (h d)") |
(b, h, t, d) | (b, t, h·d) | reshape | Attention 输出恢复 |
| Batch / Token 混合 | rearrange(x, "b t d -> (b t) d") |
(b, t, d) | (b·t, d) | view | 常用于共享线性层 |
| 保持不变(Identity) | rearrange(x, "b t d -> b t d") |
(b, t, d) | (b, t, d) | 无 | 用于代码可读性 / 占位 |
import torch
from einops import einsum, rearrange
def einstein_example1():
"""
Batched matrix multiplication with einops.einsum
"""
D = torch.rand(5, 3, 4)
A = torch.rand(3, 4)
# 普通矩阵乘法,不知道 D 和 A 具体的形状以及输出的形状
Y = D @ A.T
print(Y)
# 使用 einsum 进行矩阵乘法,可读性更好
Y = einsum(D, A, "batch sequence d_in, d_out d_in -> batch sequence d_out")
# D 可以有任意的前置维度,A 受限
Y = einsum(D, A, "... d_in, d_out d_in -> ... d_out")
print(Y)有一批图像,对于每个图像希望基于一些缩放因子生成 10 种暗淡版本
def einstein_example2():
"""
Broadcasted operations with einops.rearrange
"""
images = torch.randn(64, 128, 128, 3) # (batch, height, width, channel)
dim_by = torch.linspace(start=0.0, end=1.0, steps=10)
# Reshape and multiply
dim_value = rearrange(dim_by, "dim_value -> 1 dim_value 1 1 1")
images_rearr = rearrange(images, "b height width channel -> b 1 height width channel")
dimmed_images = images_rearr * dim_value
# Use einsum to reshape and multiply in one step
dimmed_images = einsum(
images, dim_by,
"batch height width channel, dim_value -> batch dim_value height width channel"
)Reference
[1] CS336 Assignment 1 (basics): Building a Transformer LM. Version 1.0.5
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!