CS336 Assignment 1: BPE Tokenizer's Detailed Implementation
Aug. 01, 2025 - Sep. 29, 2025 · Qiyao Wang
BPE Tokenizer
BPE Training Example (inefficient yet valid logic for understanding)
Assignment 1 给了一个用于理解 BPE 流程的简单的处理过程,我将其形成了相应的代码,但是相对低效,BPE 的训练流程及代码如下:( 所处理的文本见代码 )
- Vocabulary Initialization: 初始化一个 256+1 大小的字典,前 256 为 0-255 每个字节的表示 第 257 个 token 为 特殊 token
<|endoftext|>; - Pre-Tokenization: 将文本进行预分词,避免导致类似 "dog!" 和 "dog." 语义相近,但分词结果完全不同的情况,此处使用直接的
split函数,一般而言可以使用正则的手段进行(后续); - Merges: 每一轮,计算每个元组中相邻元素组成的新 pair 的频率,选择频率最大的(相同频率时,选择字典序大的)pair 进行合并,作为引入的新 token,经过 $N$ 次迭代(超参数,此处使用 $N=6$)
from typing import Dict
from collections import Counter
text = """low low low low low
lower lower widest widest widest
newest newest newest newest newest newest
"""
def init_vocab() -> Dict[str, int]:
"""256 byte + <|endoftext|>"""
vocab = dict()
for i in range(256):
item = {
f"{chr(i)}": i
}
vocab.update(item)
eot = {
"<|endoftext|>": 256
}
vocab.update(eot)
return vocab
def pre_tokenization(text):
text_split = text.split()
text_counter = Counter(text_split)
return dict(text_counter)
def pair_count(cand_list):
status = Counter()
for cand in cand_list:
cand_key = list(cand.keys())[0]
cand_value = list(cand.values())[0]
for i in range(len(cand_key) - 1):
# i: [0,1,2] i+1: [1,2,3] ❌
# i: [0,1] i+1: [1,2] ✅
pair = (cand_key[i], cand_key[i + 1])
status[pair] += cand_value
return dict(status)
def merge(pair_counted, cand_list):
# 频率相同时,选择字典序大的
max_freq = max(pair_counted.values())
max_pairs = [pair for pair, freq in pair_counted.items() if freq == max_freq]
max_cnt_pair = max(max_pairs)
new_cand_list = []
for cand in cand_list:
cand_key = list(cand.keys())[0]
cand_value = list(cand.values())[0]
# 判断 (a, b) slice 是否在 x1,x2,...xn 中,保持邻近顺序
is_in = any(cand_key[i:i+len(max_cnt_pair)] == max_cnt_pair for i in range(len(cand_key) - 1))
if is_in:
new_key = []
i = 0
while i < len(cand_key):
if cand_key[i:i + len(max_cnt_pair)] == max_cnt_pair:
new_key.append("".join(max_cnt_pair))
i += len(max_cnt_pair)
else:
new_key.append(cand_key[i])
i += 1
new_key = tuple(new_key)
new_cand_list.append({new_key: cand_value})
else:
new_cand_list.append({cand_key: cand_value})
return new_cand_list, max_cnt_pair
if __name__ == '__main__':
num_merges = 6
vocab = init_vocab()
pre_tokenized = pre_tokenization(text)
merges = []
for word, count in pre_tokenized.items():
item_key = tuple(list(word))
merges.append({
item_key: count
})
new_tokens = []
for _ in range(num_merges):
pair_cnt = pair_count(merges)
merges, new_token = merge(pair_cnt, merges)
new_tokens.append(new_token)
print(merges)
print(new_tokens)
new_tokens = ["".join(item) for item in new_tokens]
print(new_tokens)
for token in new_tokens:
vocab_size = len(vocab)
vocab[token] = vocab_size
print(vocab)
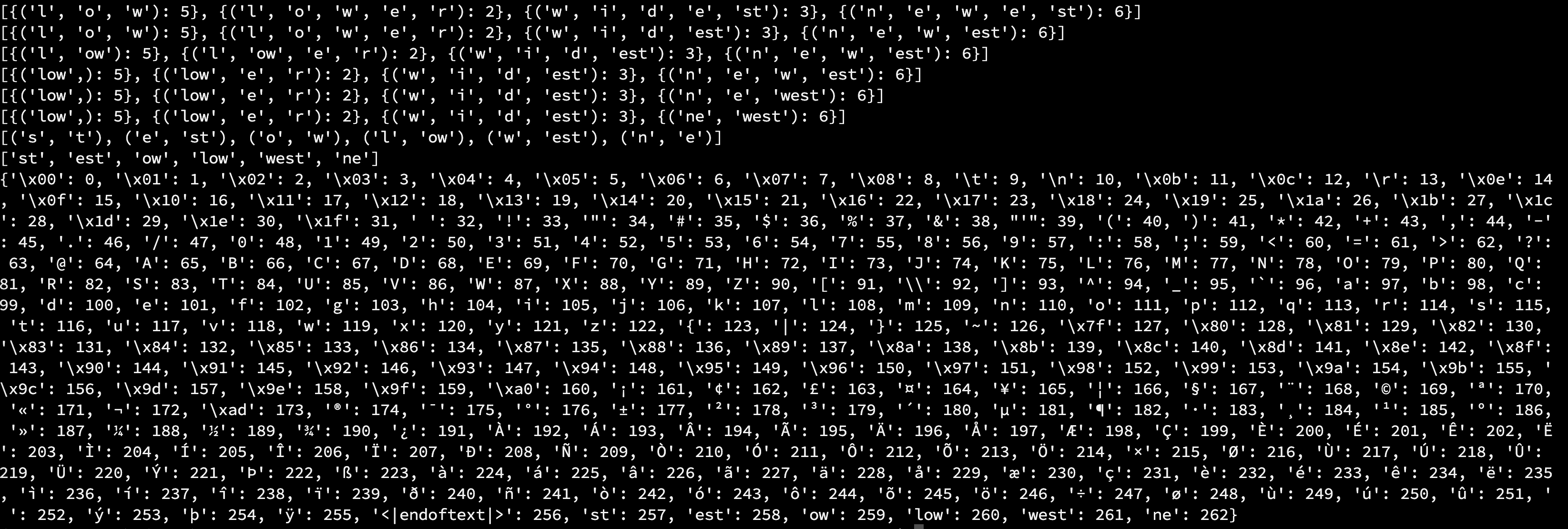
如下图 1 所示为相应的运行结果,其中代码中有步骤级的打印结果
BPE Tokenizer Training (More Efficient Manner)
对于"Problem (train_bpe): BPE Tokenizer Training (15 points)",在adapter.py中run_bpe_tokenizer()中引入bpe_tokenizer.py中的相关函数,具体实现如下
import regex as re
import os
from multiprocessing import Pool # 多线程
from typing import BinaryIO
from collections import defaultdict
import time
"""对大规模文本进行分块处理,寻找块边界,方便后续的并行处理"""
def find_chunk_boundaries(
file: BinaryIO,
desired_num_chunks: int,
split_special_token: bytes,
) -> list[int]:
"""
Chunk the file into parts that can be counted independently.
May return fewer chunks if the boundaries end up overlapping.
"""
assert isinstance(split_special_token, bytes), "Must represent special token as a bytestring"
# Get total file size in bytes
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0)
chunk_size = file_size // desired_num_chunks
# Initial guesses for chunk boundary locations, uniformly spaced
# Chunks start on previous index, don't include last index
chunk_boundaries = [i * chunk_size for i in range(desired_num_chunks + 1)]
chunk_boundaries[-1] = file_size
mini_chunk_size = 4096 # Read ahead by 4k bytes at a time
for bi in range(1, len(chunk_boundaries) - 1):
initial_position = chunk_boundaries[bi]
file.seek(initial_position) # Start at boundary guess
while True:
mini_chunk = file.read(mini_chunk_size) # Read a mini chunk
# If EOF, this boundary should be at the end of the file
if mini_chunk == b"":
chunk_boundaries[bi] = file_size
break
# Find the special token in the mini chunk
found_at = mini_chunk.find(split_special_token)
if found_at != -1:
chunk_boundaries[bi] = initial_position + found_at
break
initial_position += mini_chunk_size
# Make sure all boundaries are unique, but might be fewer than desired_num_chunks
return sorted(set(chunk_boundaries))
"""对每个chunk在tokenizer之前进行预处理、预分词、统计相应的字节对频率"""
def process_chunk(args: tuple[str, int, int, list[str]]) -> list[list[bytes]]:
input_path, start, end, special_tokens = args
"""
Processing a chunk of the input file
returns byte pair frequency counts
Args:
input_path (str): the path of input file
start (int): the start byte offset of the chunk
end (int): the end byte offset of the chunk
special_tokens (list[bytes]): the list of special tokens that should not be merged
Returns:
pre_token_bytes (list[list[bytes]])
list of tokens, each token is a list of bytes
"""
with open(input_path, "rb") as file:
file.seek(start)
chunk = file.read(end - start).decode("utf-8", errors="ignore")
"""1. Remove special tokens
Construct Regrex Pattern
| means or
re.escape(tok) escape each special character
"""
pattern = "|".join(re.escape(tok) for tok in special_tokens)
documents = re.split(pattern, chunk)
"""2. Pre-Tokenize and count byte pair frequencies"""
pre_tokens_bytes: list[list[bytes]] = []
PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
for doc in documents:
tokens = [match.group(0).encode("utf-8") for match in re.finditer(PAT, doc)]
for token in tokens:
token_bytes = [bytes([b]) for b in token]
pre_tokens_bytes.append(token_bytes)
return pre_tokens_bytes
def train_bpe(
input_path: str,
vocab_size: int,
special_tokens: list[str],
num_processes: int = 16
) -> tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
"""
Training a BPE Tokenizer on the given corpus.
:param input_path: str, training corpus path
:param vocab_size: int, size of the final vocabulary
:param special_tokens: list[str], list of special tokens
e.g. ["<|endoftext|>", ""] which directly added into vocabulary, not participate in merge process
:param num_processes: int, optional (default=8)
:return:
vocab: a dictionary mapping token IDs to token values
dict[int, bytes] {0: "0", ...}
merges: list of merged tokens, where each tuple represents two byte-level tokens
list[tuple[bytes, bytes]]
"""
start_time = time.time()
# print("Tokenizing corpus...")
# 1. Initialize Vocabulary
vocab = {
i: bytes([i]) for i in range(256)
}
for token in special_tokens:
"""After add each special token into vocab, its length +1"""
vocab[len(vocab)] = token.encode("utf-8")
# 2. Pre-tokenization
"""find_chunk_boundaries(file, desired_num_chunks, split_special_token)"""
with open(input_path, "rb") as f:
boundaries = find_chunk_boundaries(f, num_processes, "<|endoftext|>".encode("utf-8"))
"""Construct Multi-thread task"""
"""[0 : len(boundaries) - 2], [1 : len(boundaries) - 1]"""
task_args = [(input_path, start, end, special_tokens) for start, end in zip(boundaries[:-1], boundaries[1:])]
with Pool(processes=num_processes) as pool:
chunk_results = pool.map(process_chunk, task_args)
# 3. Compute BPE merges
merges: list[tuple[bytes, bytes]] = []
pre_tokens_bytes: list[list[bytes]] = [token for chunk in chunk_results for token in chunk]
counts = defaultdict(int)
pair_to_indices = defaultdict(set) # 有点类似倒排索引表
for idx, token in enumerate(pre_tokens_bytes):
for i in range(len(token) - 1): # Token is a list of bytes
pair = (token[i], token[i + 1])
counts[pair] += 1
pair_to_indices[pair].add(idx)
idx = len(vocab)
while idx < vocab_size:
if not counts:
break
max_pair: tuple[bytes, bytes] = None
max_cnt = -1
for pair, cnt in counts.items():
if cnt > max_cnt:
max_pair = pair
max_cnt = cnt
elif cnt == max_cnt:
if max_pair is None or pair > max_pair:
max_pair = pair
# pair > max_pair select the one which is lexicographically larger
merges.append(max_pair)
a, b = max_pair
new_token = a + b
vocab[idx] = new_token
idx += 1
# process affected indices: find max_pair in which token
affected_indices = pair_to_indices[max_pair].copy() # ! Note this copy
for j in affected_indices:
token = pre_tokens_bytes[j] # find the token which contains the max_pair
for i in range(len(token) - 1): # change the consists of current token
old_pair = (token[i], token[i + 1])
pair_to_indices[old_pair].discard(j)
# 去除倒排索引表中的docid
counts[old_pair] -= 1
# 合并后,token中其他的pair也要变化
if counts[old_pair] == 0:
counts.pop(old_pair)
pair_to_indices.pop(old_pair, None)
merged = [] # 合并后
i = 0
while i < len(token):
if i < len(token) - 1 and token[i] == a and token[i+1] == b: # Location a+b
merged.append(new_token)
i += 2
else:
merged.append(token[i])
i += 1
pre_tokens_bytes[j] = merged
token = pre_tokens_bytes[j]
for i in range(len(token) - 1):
pair = (token[i], token[i + 1])
counts[pair] += 1
pair_to_indices[pair].add(j)
end_time = time.time()
print(f"BPE training finished in {end_time - start_time:.2f} seconds")
return vocab, merges
上述代码,处理TinyStories数据集耗时3小时 (11480.69s),应进行优化;对于owt数据集则需要更长的时间,如何加速?
TODO List
- 分析BPE Tokenizer速度慢的原因,各环节耗时
- 设计方式加速BPE Tokenizer
Reference
[1] CS336 Assignment 1 (basics): Building a Transformer LM. Version 1.0.5
[2] Stanford CS336 | Assignment 1 - BPE Tokenizer Training 实现
Contact
There may be some errors present. If you find any, please feel free to contact me at wangqiyao25@mails.ucas.ac.cn. I would appreciate it!