Large Language Models for Patent
Team: Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences; Dalian University of Technology
Student Member: Qiyao Wang
News
- [2024-12-20] 🥳 The AutoPatent has been fortunate to receive attention and coverage from Xin Zhi Yuan, and it will continue to be expanded and improved in the future.
- [2024-12-13] 🎉 We release the first version of AutoPatent.
Introduction
Our Work
*Equal Contribution and † Corresponding Author
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Qiyao Wang, Guhong Chen, Hongbo Wang, Huaren Liu, Minghui Zhu, Zhifei Qin, Linwei Li, Yilin Yue, Shiqiang Wang, Jiayan Li, Yihang Wu, Ziqiang Liu, Longze Chen, Run Luo, Liyang Fan, Jiaming Li, Lei Zhang, Kan Xu, Hongfei Lin, Hamid Alinejad-Rokny, Shiwen Ni†, Yuan Lin†, Min Yang†

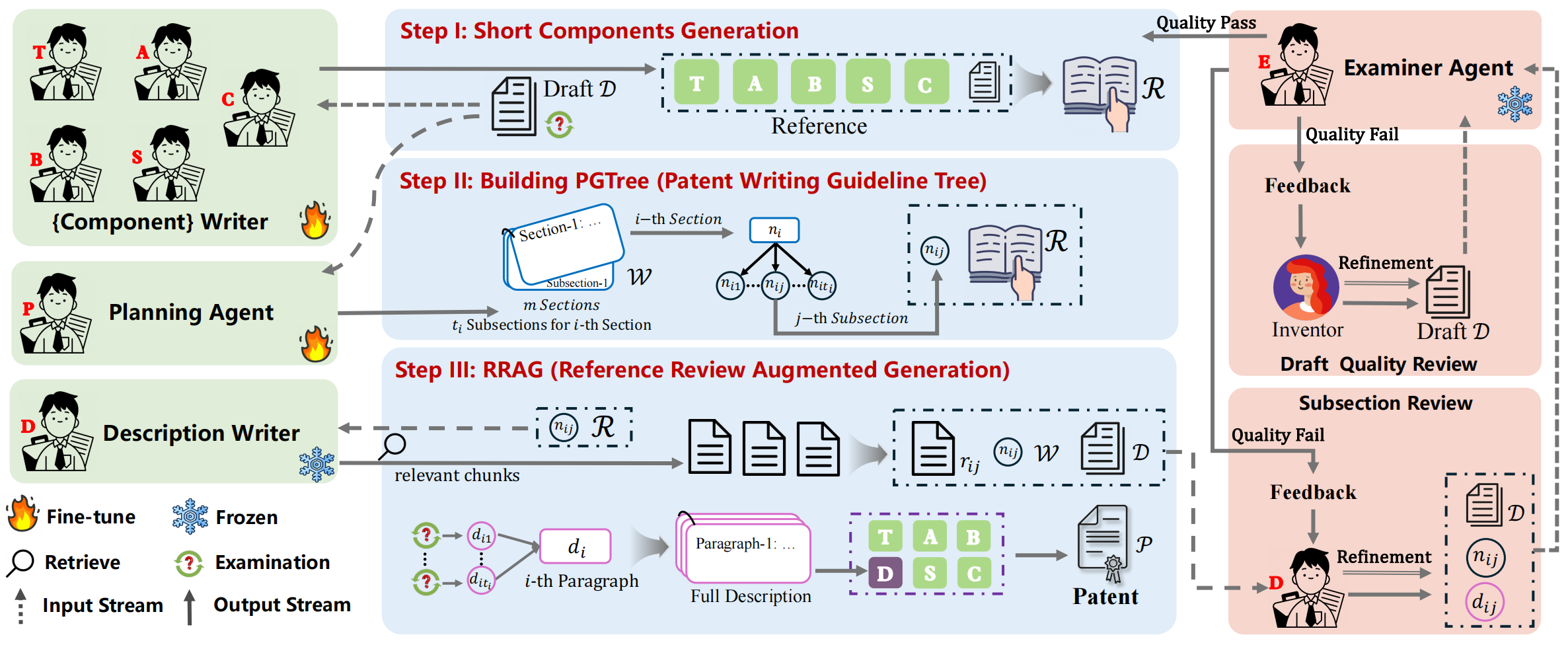
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Qiyao Wang*, Shiwen Ni*, Huaren Liu, Shule Lu, Guhong Chen, Xi Feng, Chi Wei, Qiang Qu, Hamid Alinejad-Rokny, Yuan Lin†, Min Yang†
TL;DR: We introduce Draft2Patent, a novel task for generating full-length patents (~17K tokens) from drafts, along with the D2P benchmark. Our AutoPatent framework, leveraging a multi-agent system, excels in patent generation, with Qwen2.5-7B outperforming larger models like GPT-4o and Qwen2.5-72B in metrics and human evaluations.


Qiyao Wang, Jianguo Huang, Shule Lu, Yuan Lin†, Kan Xu, Liang Yang, Hongfei Lin
TL;DR: IPEval introduces a benchmark for assessing Large Language Models' (LLMs) performance in intellectual property (IP) law with 2,657 questions. It evaluates LLMs across key IP areas using zero-shot, 5-few-shot, and Chain of Thought (CoT) approaches. Findings highlight the need for specialized IP LLMs due to language proficiency bias. The benchmark is crucial for developing LLMs with deeper IP knowledge.
Website |
Paper |
Github |
HuggingFace
